How to build an AI visibility audit that holds up to scrutiny: with metrics you can compute, a clear failure taxonomy and actions prioritized by commercial impact. From theory to the real step-by-step with the platform we use at Elevam for this: Antropus.
Want to skip the theory and have us do it for you? Request a GEO audit for your brand and we'll show you exactly where you appear (and where you don't) in AI answers.
1. What a GEO audit is (and why it isn't SEO)
Let's start with the definition, because half the industry uses it wrong.
A GEO audit (from Generative Engine Optimization) is the process of measuring, evaluating and diagnosing a brand's presence in generative artificial intelligence engines. Specifically, across six surfaces:
- ChatGPT (OpenAI)
- Claude (Anthropic)
- Gemini (Google)
- Perplexity (Sonar)
- Google's generative mode (the conversational answer inside Google itself)
- Google AI Overview (the generative block that appears above the organic results)
Classic SEO answers "what position do I hold on Google for this keyword?". An AI visibility audit answers a different and, today, more urgent question:
When a user asks an AI about my sector, does my brand appear? In what position? Do they cite my site or a competitor's? Does the AI really know me or does it confuse me with another company?
The difference isn't one of nuance, it's one of nature. Google Search Console gives you impressions, clicks, CTR and average position. Generative models give you none of that. When someone asks ChatGPT, they get a written text, sometimes with sources and sometimes without. Nobody tells you that your brand showed up, that you were confused with another, or that your competitor was recommended. The answer is, literally, a black box.
To open that box you need a systematic, repeatable measurement protocol. That, and not a handful of screenshots, is a GEO audit.
“SEO tells us how Google finds us. GEO tells us how an AI describes us. And more and more buying decisions begin in the second conversation, not the first search.
”
1.1 Classic SEO, GEO and AI measurement: three different things
| Discipline | What it measures / Data source |
|---|---|
| Classic SEO | Organic position on Google, impressions, clicks, backlinks · Search Console and SEO data providers |
| GEO | How the brand appears in AI engines: frequency, position, citation, entity confusion · Own tests against the AIs + an analyzer |
| AI measurement | The layer that unites both worlds: separates what comes from the search engine from what comes from the assistant · Antropus orchestrates and compares it |
Today a serious client needs all three. But this guide is about the middle one, which is the one almost nobody knows how to do well.
2. Why your brand needs an AI visibility audit now
It's not a fad. It's a change of channel, and it's moving fast.
When someone asks "best GEO agency in Spain" on ChatGPT and is satisfied with the answer, that user never reaches Google. The traffic you capture in search for that intent is, increasingly, only the fraction the AI didn't resolve. In other words: what you see in Search Console is the tip of the iceberg, and the iceberg is growing below the waterline, where your classic analytics doesn't look.
The size of that "below the water" is no longer anecdotal. According to OpenAI (February 2026), ChatGPT exceeds 900 million weekly active users and is approaching a billion. Add the hundreds of millions on Gemini, Claude's base and Perplexity's growth as an alternative search engine, and you have entire audiences that your classic SEO strategy simply doesn't measure.
And then there's Google playing both boards at once: in a great many informational searches and quite a few commercial ones, the AI Overview block appears above the organic results. If your brand doesn't make it into that synthesized answer, you've lost the click before the user even reaches the list of blue links.
So the question isn't whether you're going to need to measure your AI visibility. The question is when you find out you were already losing it and nobody warned you.
2.1 What concrete problems a well-built GEO audit solves
A serious audit lets you, in practice:
- Know whether your brand appears (or not) in answers to real questions in your sector.
- Detect whether the AI knows you well or confuses you with a homonym. It has happened with our own brand: in certain tests, Elevam appeared confused with ElevenLabs.
- See whether the AI recommends your competition in your place, and in exactly what type of questions.
- Identify which URL of your site the AI cites and whether it's the right one for that intent.
- Discover cannibalization: your blog taking the spot that should belong to your services landing page.
- Quantify how many of your appearances are strong recommendations and how many are filler mentions with no commercial value.
- Have a quantitative, quarter-over-quarter comparable baseline to know whether your optimization actions are working or not.
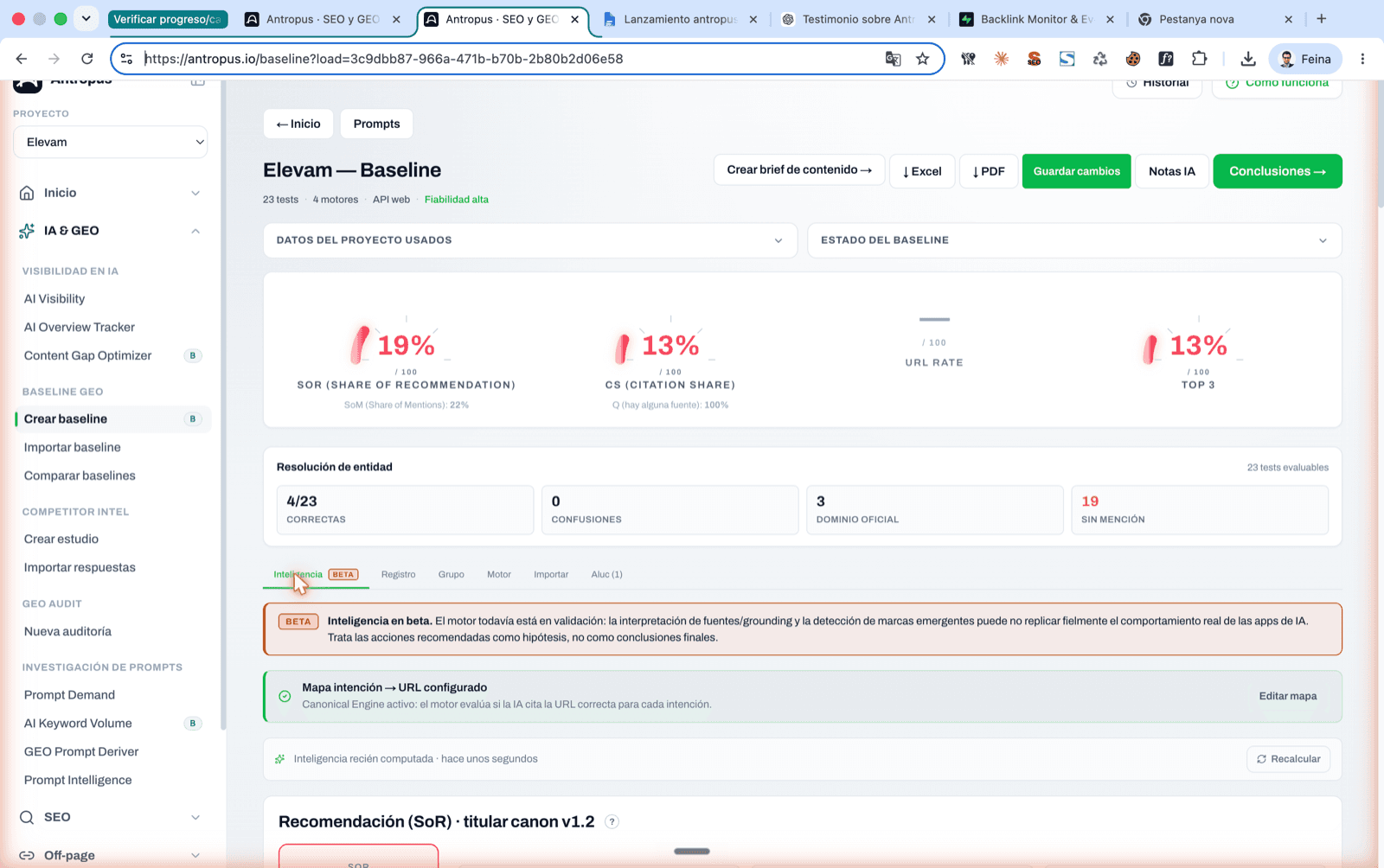
Main screen of a finished baseline in Antropus, with the 4 headline indicators (SoR, CS, URL Rate, Top 3) and entity resolution.
3. The mistake most GEO audits make
Before explaining how we do it at Elevam, we have to dismantle what's being sold out there. Most of the "GEO audits" that reach our hands —usually when a client shows us the one they had done before— fail on at least one of these three points. And all three have the same effect: a report that looks good and is useless.
3.1 Prompts biased toward the brand
It's the most common mistake and the most expensive. The consultant fires 30 questions at ChatGPT, but they're all of this style:
- "What do you think of [brand]?"
- "Reviews of [brand]"
- "Is [brand] trustworthy?"
- "Compare [brand] with [competitor]"
The AI is forced to talk about the brand in every answer, because the prompt names it. The result: a 90% Share of Mentions. The consultant shows it to the client as a triumph. They're not measuring anything useful.
What the client needs to know is whether the AI recommends them when the user doesn't yet know them. And that's only measured with blind questions, of the type:
- "What's the best SEO agency in Madrid?"
- "Recommend platforms to manage GEO"
- "What tools do agencies use to measure their AI visibility?"
If your brand doesn't show up there, you're not capturing new demand in AI. As simple as that. And if your audit doesn't measure this, your audit isn't an audit: it's the consultant's sales brochure to justify the next invoice.
3.2 Binary metrics disguised as weighted metrics
The second failure: using Share of Mentions (SoM) as the headline metric. SoM is binary: it counts whether the brand appeared or not, and nothing more. It doesn't distinguish the strength with which you're recommended.
Compare these two answers:
- "I recommend [brand]; it's the best option on the market, and here's why…"
- "There are many options; some are X, Y, Z, and there's also [brand]."
Both add exactly the same to SoM. But the first is worth ten times the second. Without a metric that weights the strength of the recommendation, your audit throws away half the information that matters.
The metric that does weight is SoR (Share of Recommendation), and it's the headline metric of the Antropus dashboard. The problem is that the market doesn't use it yet, so almost nobody reports it. We return to it in detail below.
3.3 Rigged denominators
The third is statistical, looks minor and ruins entire reports. Imagine you fire 30 prompts at Gemini with web active and 8 fail technically (timeout, exhausted quota). You can't compute your Citation Rate as 2 / 30 = 6.6%. Those 8 are not "answers in which you weren't cited"; they're answers that never came to exist. The honest calculation is 2 / 22 = 9%.
The same data, two denominators
One denominator detail, a huge difference in the report: counting the 8 failed tests as "they didn't cite me" underestimates your presence and hands over a falsely alarming diagnosis.
4. The six mandatory prompt categories (A–F): the heart of the methodology
A serious GEO audit doesn't let you write the questions however you like. It forces a methodological distribution that neutralizes brand bias. At Antropus we call them categories A–F, and they're mandatory in every baseline.
4.1 The catalog
| Cat. | Name | What it measures | Brand policy | Default % |
|---|---|---|---|---|
| A | Brand and reputation | Whether the AI knows your brand and what it knows about it | Always with brand | 10–15% |
| B | Generic discovery | Whether you appear when the user does NOT know you | Never with brand | 25–30% |
| C | Competitive comparison | Whether you appear as an alternative against competitors | Moderate | 20–25% |
| D | Commercial decision | Whether you appear at the moment of buying | Never with brand | 15–20% |
| E | Product / category | Whether you appear in technical or catalog searches | Never with brand | 10–15% |
| F | Objections and trust | Whether you appear when the user has doubts | Rare | 10–15% |
4.2 Why exactly this distribution
Behind it there are three hard rules, which at Antropus are not a recommendation but code that runs:
- Category A never exceeds 30% of the set. If you go over, you're measuring brand reputation, not GEO visibility.
- B + C + D add up to at least 51%. It's the blind, commercial majority: where it's really decided whether you capture new demand.
- All six categories must be present if the set has six prompts or more. Covering only three or four biases the reading.
And underneath there's a priority order for small sets (fewer than 12 prompts): B → D → C → A → E → F. That is, if you can only fire six questions, you spend them in that order; you don't start with A out of narcissistic inertia.
4.3 What happens if you skip these rules
If you fire 30 prompts where 25 are category A (all with your brand inside), your SoM will come out between 70% and 95%. You show it to the client as a success. And the next quarter, when you "optimize" again, nothing will have changed: because the audit wasn't measuring anything that could move.
Antropus refuses to compute certain metrics if the evaluable sample is smaller than 5, and explicitly warns when the set has fewer than 12 prompts ("doesn't cover the full methodology") or fewer than 15 ("minimum sample recommended to draw conclusions"). We prefer an honest "—" to a number that misleads.
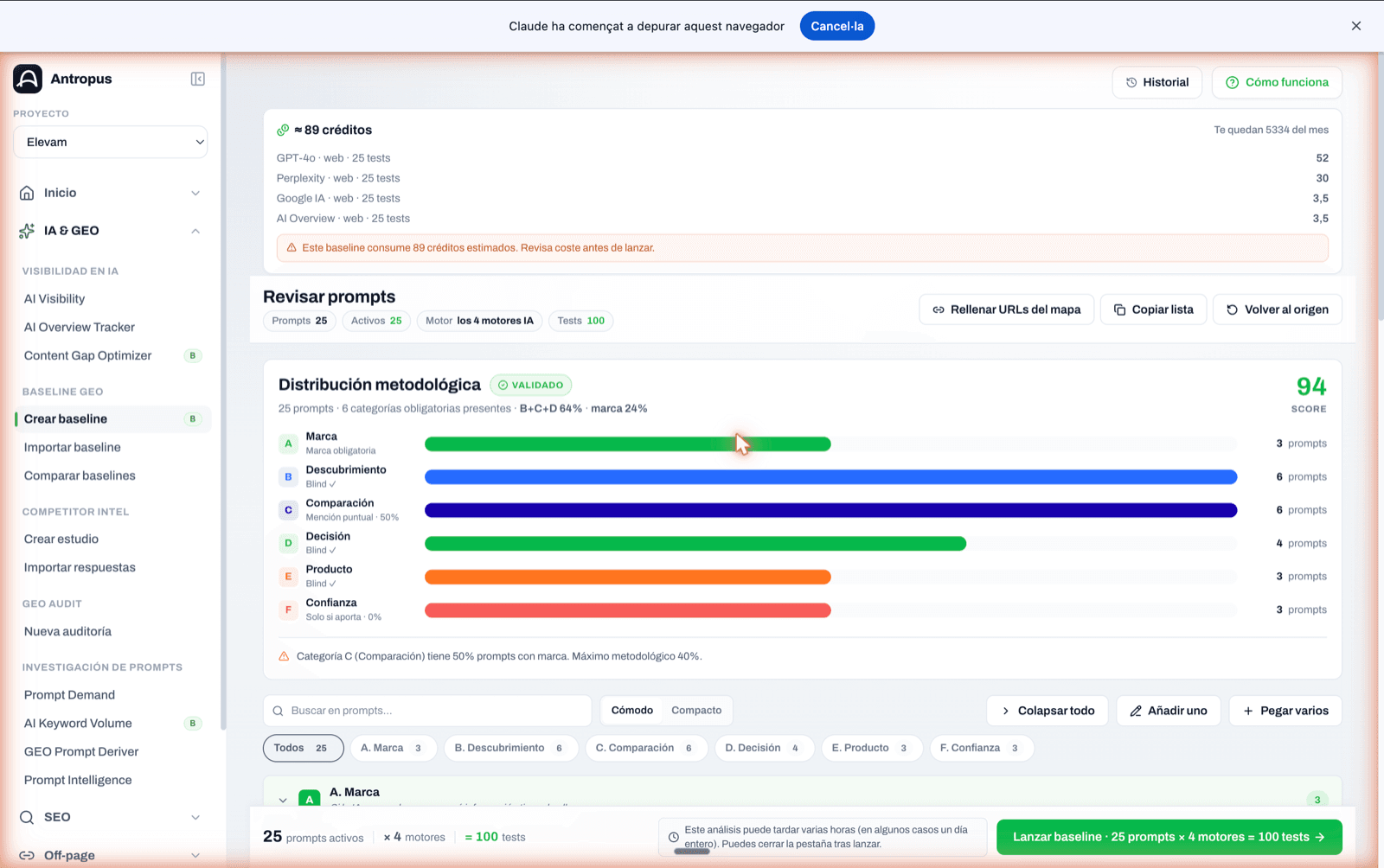
Methodological distribution panel of a baseline under review. Score 82 and warnings when B+C+D doesn't reach 51% or when there are fewer than 12 prompts.
5. The metrics that matter: what's measured and how it's computed
A serious GEO audit reports between four and six headline metrics, each with its declared denominator. Not twenty loose metrics without context. These are the ones we paint on the Antropus dashboard.
SoR
Share of Recommendation
The headline. Average strength with which the AI recommends you.
BCR
Brand Citation Rate
% of answers that cite a source from your official domain.
R
URL Rate
% of answers that cite the expected canonical URL.
Top 3
Top 3 Share
% of ordered rankings where you appear in positions 1-3.
5.1 SoR — Share of Recommendation (the headline)
What it measures: the average strength with which the AI recommends you. It's the only metric that weights the quality of the appearance, not just its existence.
How it's computed: the average of the recommendation weight (rsw) over the answers in which that weight was measured. The values are discrete:
| rsw | Meaning |
|---|---|
| 1.0 | You appear as the main option or featured recommendation |
| 0.75 | You're on the shortlist, with good justification |
| 0.5 | You're mentioned neutrally or as a secondary alternative |
| 0.25 | You appear in passing, without a clear recommendation |
| 0.0 | You appear, but as a discarded or discouraged option |
| null | Not measured (old baselines without re-scoring) |
The detail almost nobody respects: the "not measured" value is filtered out of the calculation. It does not count as 0. Confusing "I didn't measure it" with "it's the worst option" would corrupt the SoR of any old baseline.
5.2 BCR — Brand Citation Rate
What it measures: the percentage of answers where at least one source from your official domain appears.
It's the main citation metric, because it measures whether the AI attributes what it says to a source of yours and not to a third-party blog or a competitor. Being mentioned is good; being cited as a source is much better.
5.3 R — URL Rate (the correct URL)
What it measures: the percentage of answers where the AI cited the expected canonical URL for that intent.
The key is in the denominator: only the tests with a canonical URL mapped in your Intent URL Map enter. If an intent has no defined cluster, that test leaves the calculation. That way you don't inflate the metric with samples where there was nothing to evaluate.
5.4 Top 3 Share
What it measures: the percentage of answers with an ordered ranking in which you appear in positions 1, 2 or 3.
Important methodological detail: the denominator is NOT total visibility, but only the answers with an ordered ranking (numbered lists, explicit comparisons, shortlists). A narrative answer that mentions you without a list structure doesn't enter. Computing a Top 3 over answers without ranking means nothing.
5.5 Auxiliary metrics (but in no way accessory)
| Metric | What it measures |
|---|---|
| SoM (Share of Mentions) | Binary: % of answers where you appear. Diagnostic, never headline. |
| Validity Rate | % of methodologically valid tests (no entity confusion or topic drift) |
| Triggering Rate | Only in Google AI Overview: % of searches where Google shows the generative block |
| Source Reliability | 0–100 score of source reliability (penalizes opaque redirects) |
| Hallucination Rate | % of answers with a factual error, entity confusion or wrong attribution |
| Fragile recommendation | % of strong recommendations (rsw ≥ 0.75) based on a hallucination: high-risk visibility |
| Source Dispersion Index | Own URLs competing for the same intent: measures cannibalization |
| Competitor Leakage | % of answers where competitor URLs appear |
5.6 The nine groupings of the metrics engine
Here's part of the real power: each metric is computed not only globally, but grouped by engine, mode (memory / web), category A–F, intent, demand type, strategic role, funnel stage and expected canonical URL.
That lets you answer the questions a client actually asks: "In which engine am I doing worst?", "What type of question best activates my brand?", "Which URL of my site is performing most?", "In which specific intent am I losing share to my competition?". And all without exporting to Excel or wrestling with pivot tables.
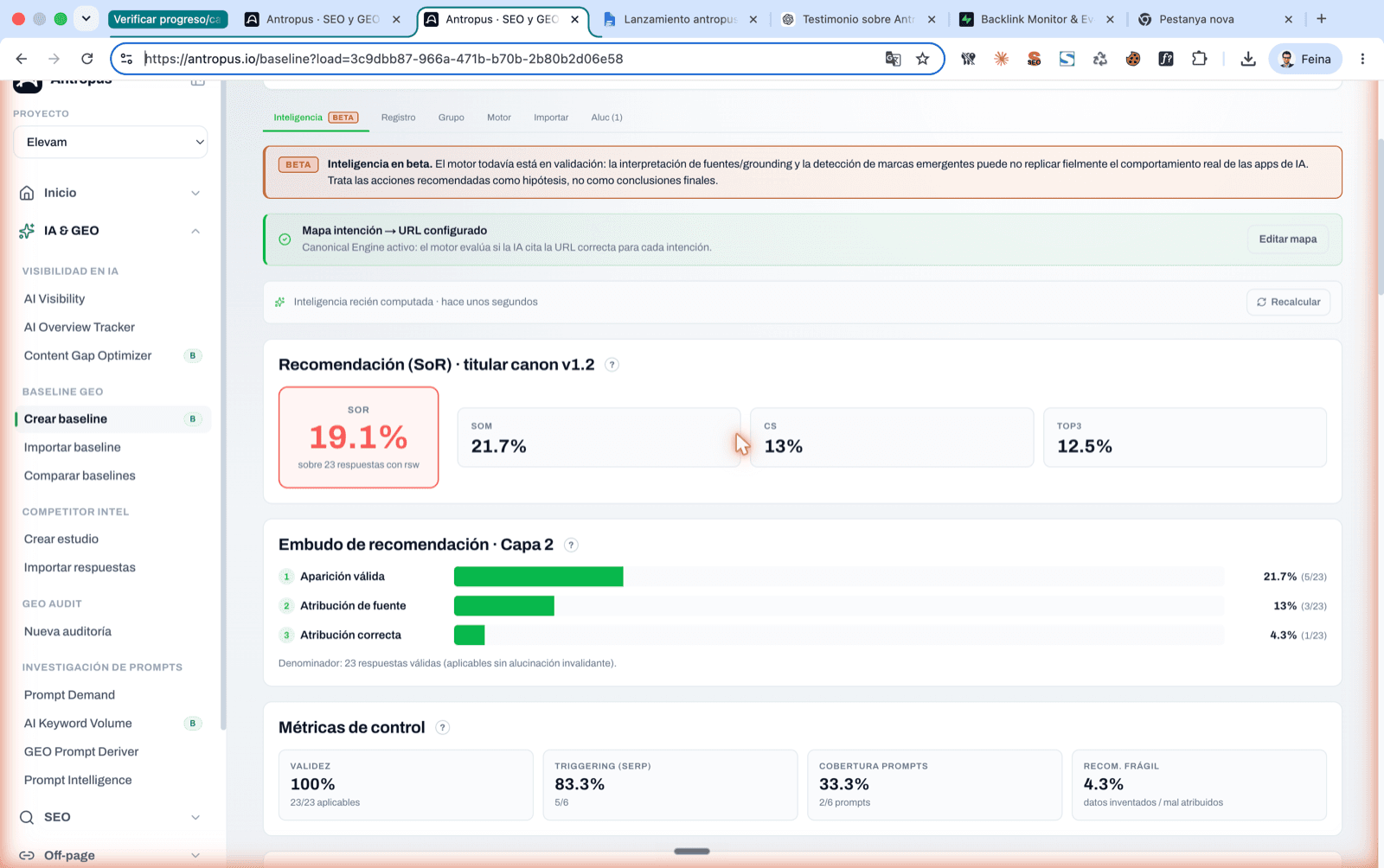
SoR indicator (canon v1.2 headline) and three-layer recommendation funnel: valid appearance → source attribution → correct attribution.
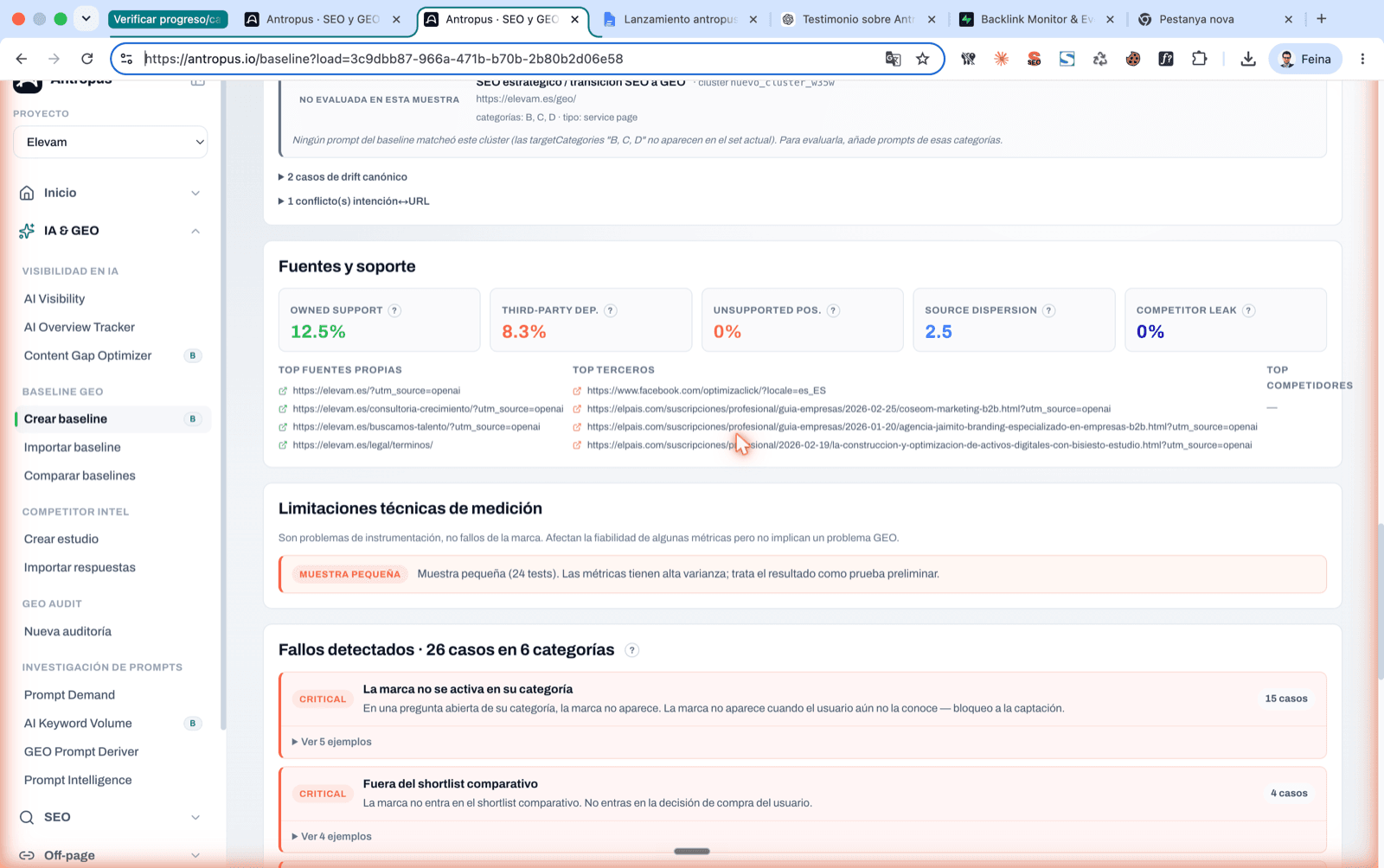
6. The intent → canonical URL map: the piece almost nobody looks at
Here's one of the most serious —and most ignored— differentiators of a well-built GEO audit. Almost every tool measures "did the AI cite any URL of your domain?" as a yes/no. And that falls short.
What really matters is:
Did it cite the correct URL of your domain for that intent?
If a user asks "best GEO agency in Madrid" and the AI cites your blog (/blog/que-es-geo/) instead of your services landing page (/servicios/geo-madrid/), technically "you were cited". But you're giving away the commercial click to an informational page that probably doesn't convert. We call this canonical drift.
6.1 What the intent map is
The Intent URL Map is a project-level configuration where you declare, for each intent cluster, what the expected canonical URL of your site is. Each cluster carries:
- Name (e.g. "GEO Services Madrid", "Brand / reputation", "Comparison vs SEMrush")
- Expected canonical URL (the optimal one for that intent)
- Acceptable URLs (others of yours that also count as a hit)
- Problematic URLs (the ones that should NOT appear here, with their reason)
- Methodological categories it covers (which of A–F)
- Strategic role (entity recognition, commercial capture, comparison shortlist, etc.)
6.2 The ten canonical classifications
For each test, the canonical engine classifies the answer into one of ten categories, with a score from 0 to 100:
| Classification | Score | Meaning |
|---|---|---|
| Correct canonical | 100 | Cites the exact canonical URL |
| Acceptable cluster URL | 75 | Cites an acceptable URL from the same cluster |
| Own URL, wrong intent | 50 | Cites a URL of yours, but not the canonical nor an acceptable one |
| Research asset absorbing commercial intent | 40 | Your blog/resources absorb commercial intent |
| Home absorbing specific intent | 35 | Your home absorbs a specific intent |
| External source replacing own asset | 25 | They cite third parties but no URL of yours |
| Source dispersion | 20 | Several of your URLs compete for the same intent |
| No canonical available | 0 | There are URLs, but the map declares no canonical |
| Wrong domain | 0 | The cited URLs are not from your domain |
| No URL | 0 | There are no URLs in the answer |
6.3 What the canonical engine returns
- A global canonical-alignment score (0–100), computed only over evaluable tests: "no URL" and "wrong domain" are not drift, they're non-activation, and they don't contaminate the score.
- Your strongest canonical URLs (the ones that get consistent hits) and the weakest (the ones that appear with a low score).
- The drift cases: a concrete list of answers where the AI cited a wrong URL of yours, with its engine, its prompt, the expected URL and the one actually cited.
- The dispersion cases, grouped by intent.
- The URL conflicts: pages you marked as problematic that are indeed appearing.
6.4 Why this is billable agency work
When you deliver a report with real drift cases, you're not giving the client an opinion. You're telling them: "Here are 12 cases where your blog is absorbing searches that should go to your services landing page. Here's the reason. Here's the URL that should show up. Here's the one that does. And here's the action: reinforce canonical signals on the landing and tone down the commercial language of the post."
That's diagnosis with evidence. And it's work that you, as an agency, can charge for without blushing.
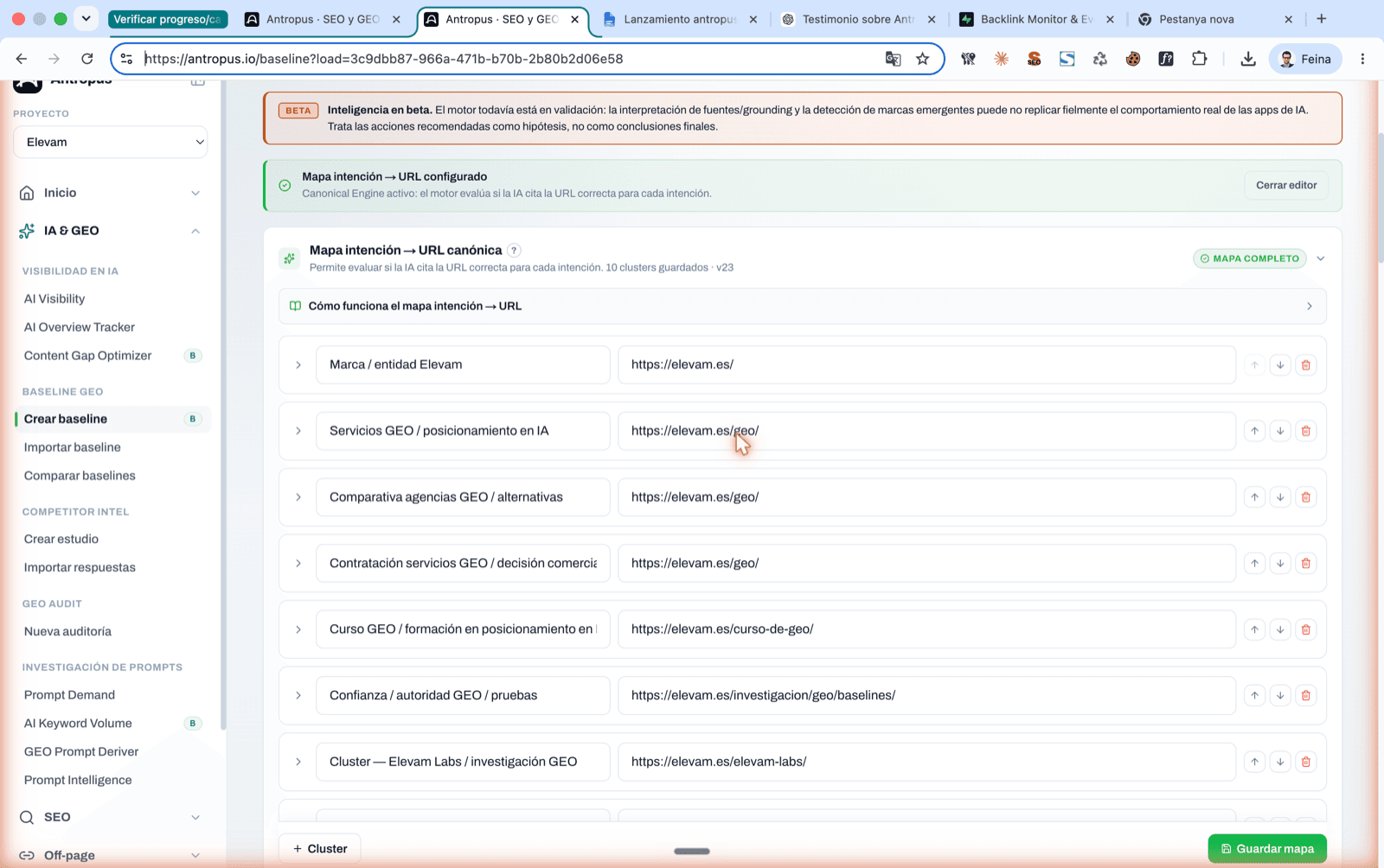
Editor of the Antropus Intent URL Map. List of 10 real project clusters with expected canonical URL per intent and a "Map complete" badge.
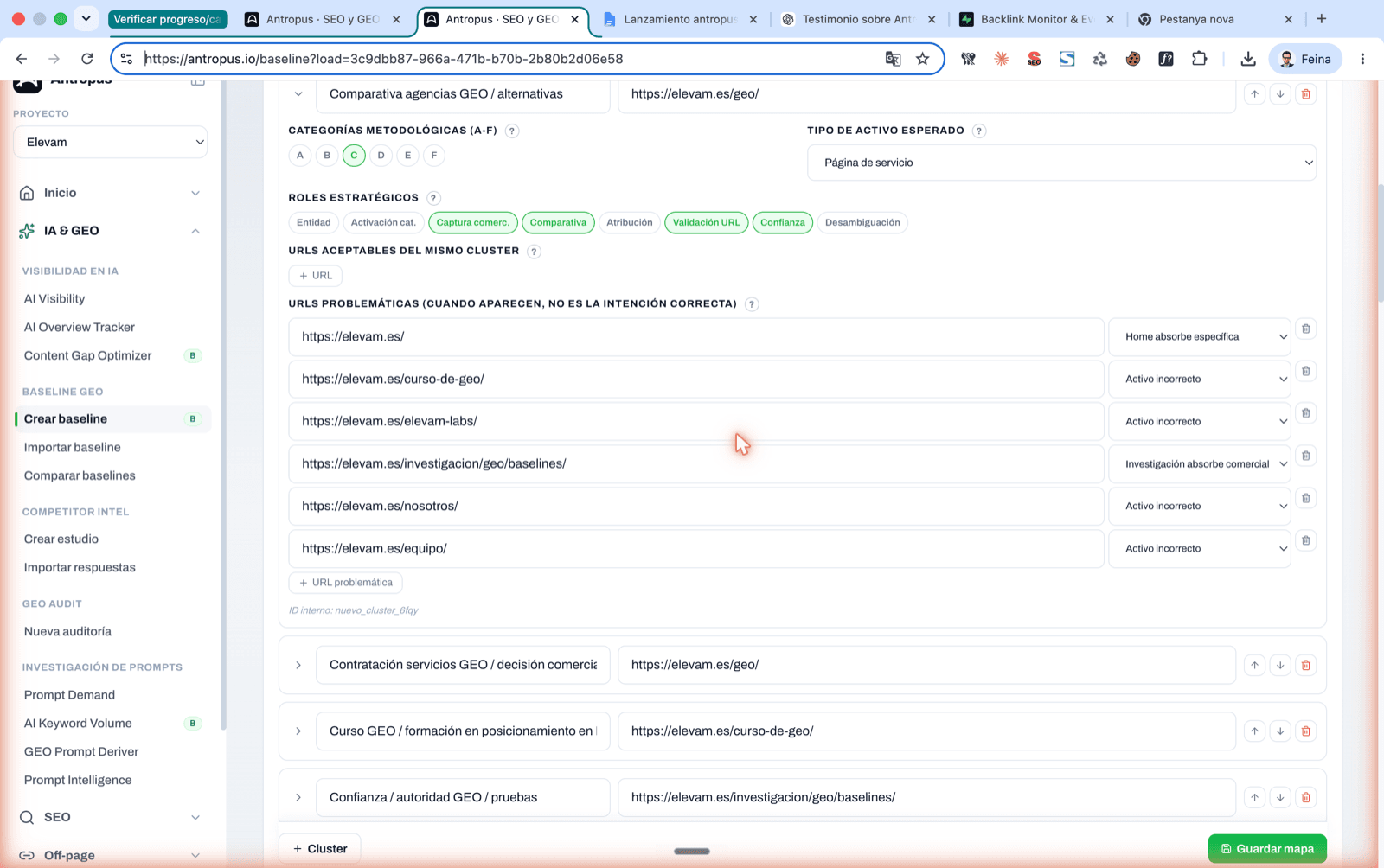
Detail of an expanded cluster: acceptable URLs from the same cluster + problematic URLs with their reason (home absorbs specific, research absorbs commercial).
7. How to launch your first GEO audit with Antropus, step by step
Let's get to it. This is, literally, what you'd do today from scratch to audit the AI visibility of a new client. The Antropus wizard has three steps: what to measure, how to measure and review.
7.1 Step 1 — What to measure: project identity and entity profile
Before touching anything, you configure the project: brand, domain, sector, country and up to three explicitly declared competitors. All of that fills in from the project profile if it already exists.
And right after, you complete the entity profile (Entity Profile). This is what will let the analyzer tell your real brand apart from any homonym. Without a solid profile, the results come out contaminated at the root. The nine fields we always fill in:
- Canonical name (minimum 3 characters, not a URL)
- Official domain (without protocol or www)
- Canonical description (factual, ideally 120 characters or more)
- Disambiguation text (one or two sentences about which entities NOT to confuse you with)
- Aliases (other names the brand may appear under)
- Related entities (your own people, products or concepts that confirm the answer is about you)
- Entities not to confuse (the similarly named ones that are NOT you)
- Expected definitions (your own terms and their canonical definition)
- Official URLs (the ones that count as a correct citation beyond the root domain)
If your brand has a short name or a homonym, this step is critical. Antropus includes an "Analyze site and propose profile" assistant that researches the brand in public sources and fills in the fields. It never overwrites: it shows you the change field by field and only applies it if you confirm.
The screen shows you at all times the profile's state with a badge ("Ready for baseline", "Usable but weak", "Incomplete", "Possibly invalid") and the completeness percentage. If the profile is in either of the two worst states, Antropus explicitly advises against launching the baseline.
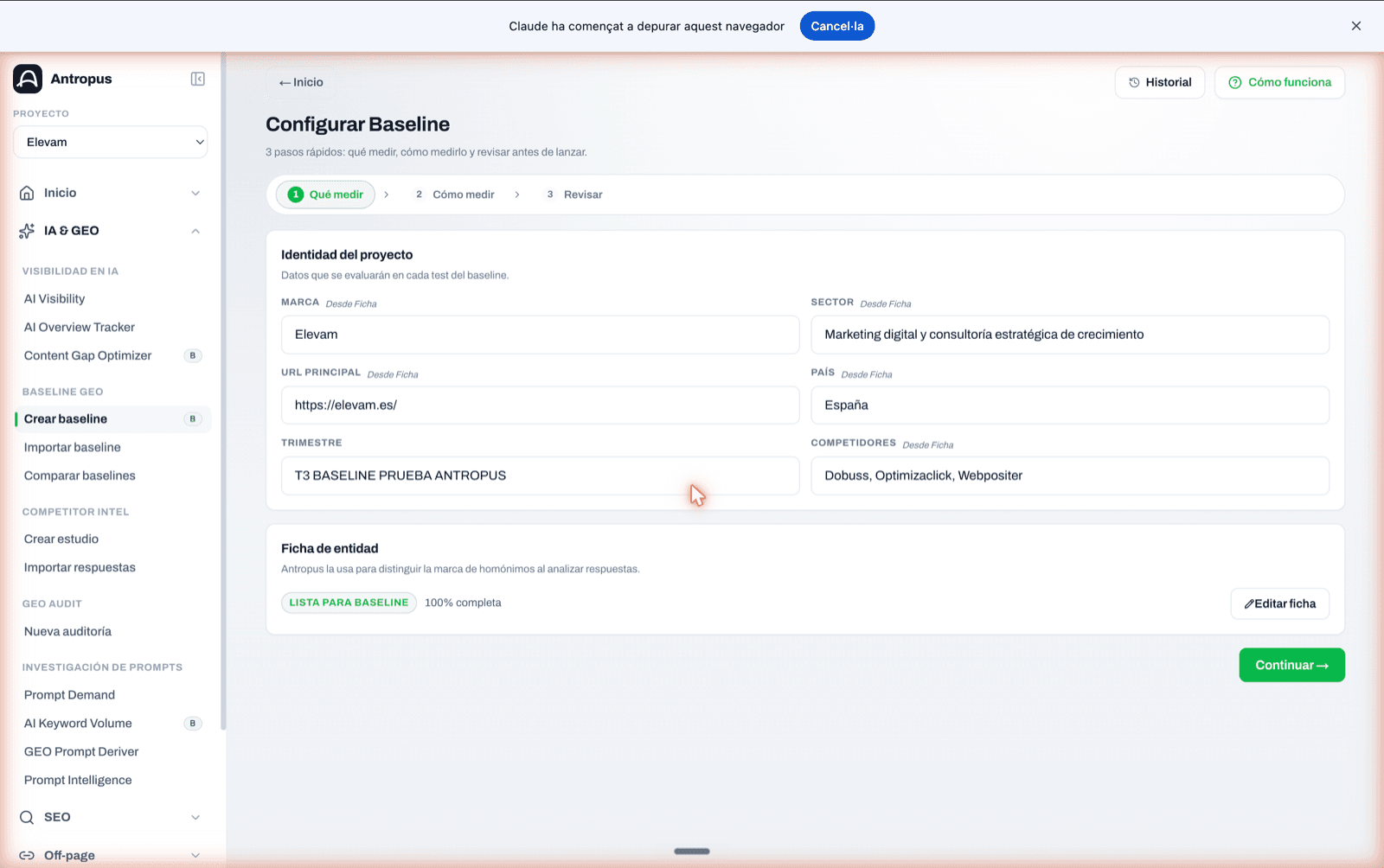
Step 1 of the "What to measure" wizard: project identity filled from the profile and green badge "Ready for baseline · 100% complete" in the Entity Profile section.
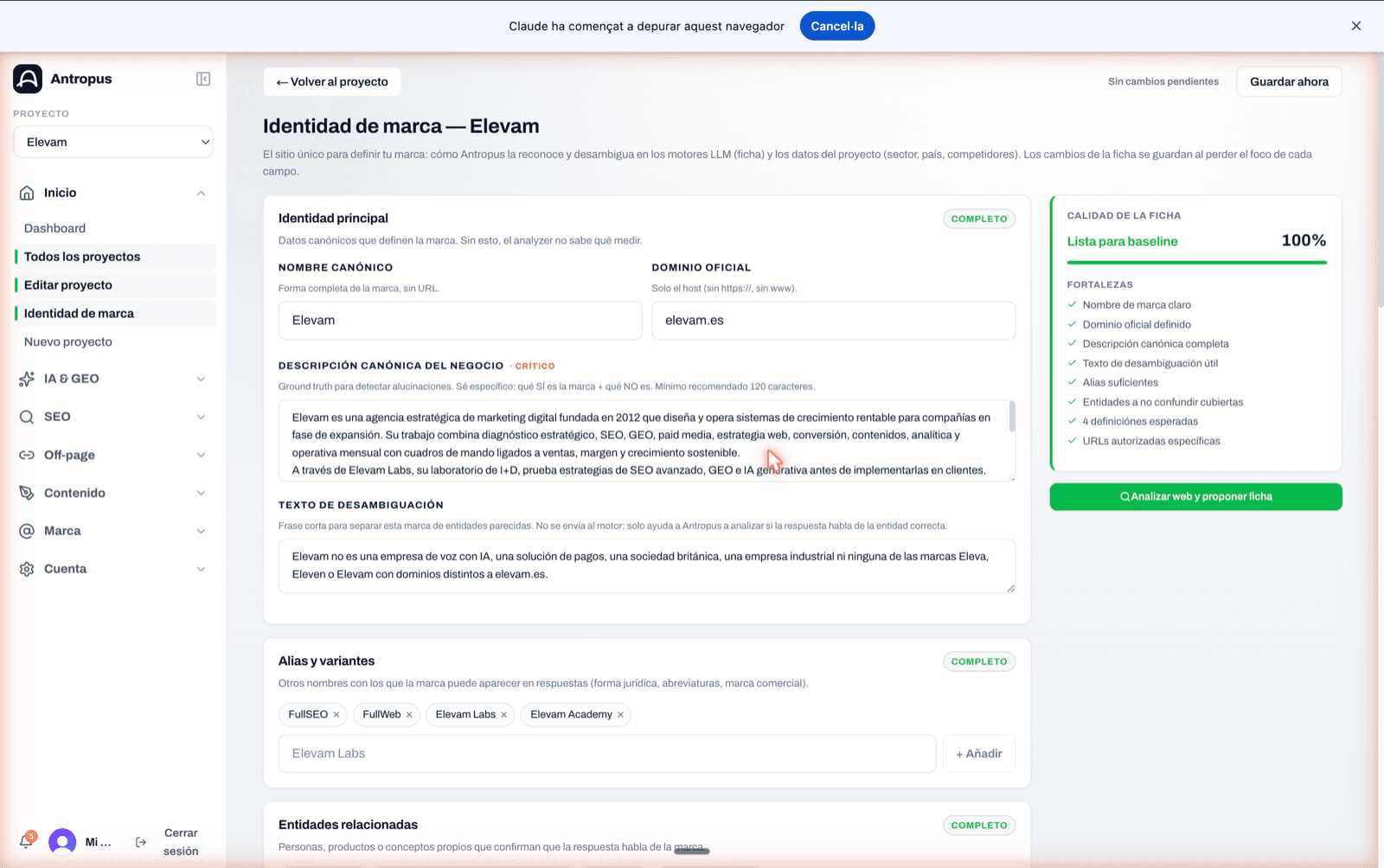
Brand Identity editor (Entity Profile). Side panel with 100% quality, "Ready for baseline" status and a list of detected strengths.
7.2 Step 2 — How to measure: engines, prompt source and depth
Here you decide exactly what you test your brand's visibility with. Three blocks:
Engines. Antropus lets you manually select, one by one, which sources the baseline runs on. The ones available today are six: Claude, ChatGPT, Gemini, Perplexity, Google AI (generative mode) and Google AI Overview (the real SERP block). There are no presets: you choose. The more engines you enable, the more reliable the reading, but also the higher the cost.
Prompt source. Three options: automatic methodological generation (Antropus creates the prompts respecting A–F), using a saved set from the project library, or adding manually (pasting or typing). For a first audit we use the automatic one; for recurring audits, the saved set, which guarantees we compare apples to apples quarter over quarter.
Baseline depth. A slider from 5 to 25 prompts. The screen indicates whether the choice is "Minimum measurement" (≤ 5 prompts, a quick test with limited coverage) or whether it enters the methodologically solid zone (≥ 12 prompts). The A–F chips below remind you which categories the set will cover.
The choice of "5 prompts × 4 engines = 20 tests" isn't the usual one for a real client. For a serious client we recommend at least 15 prompts and 3 engines, which gives between 45 and 60 tests. For a flagship audit, 30 prompts × 4 engines ≈ 120 tests.
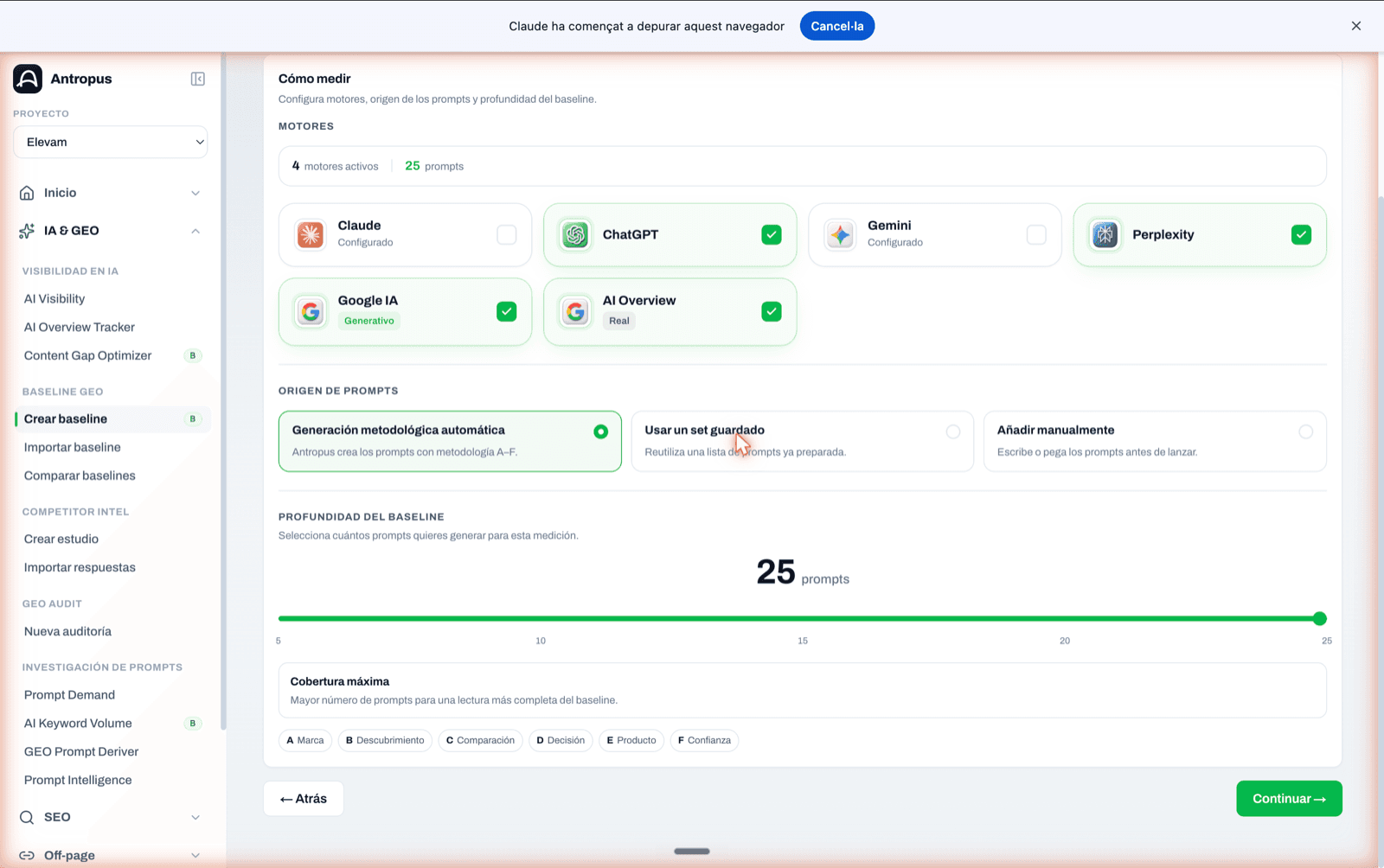
Step 2 "How to measure". Manual selection of the available engines, prompt source and baseline depth slider.
7.3 Step 3 — Review and configure the intent map
Before launching anything, Antropus shows you a summary: active engines, number of prompts, number of resulting tests, estimated cost in credits, brand, URL, sector, country, competitors and prompt source. It's the last chance to change something without having spent.
In this same step 3, collapsed, is the intent → canonical URL map editor. If the project already had a map configured, you see a "Map complete" badge and the number of saved clusters. If not, you can configure it right here without leaving the flow: each cluster with its canonical URL, its acceptable URLs and its problematic URLs, with the reason why they're problematic (home absorbs specific, research absorbs commercial, wrong asset, etc.).
This step is optional, but highly recommended: without a map, the basic metrics (SoR, BCR, Top 3) still work, but you lose 80% of the structural analysis —drift, cannibalization, architecture recommendations—.
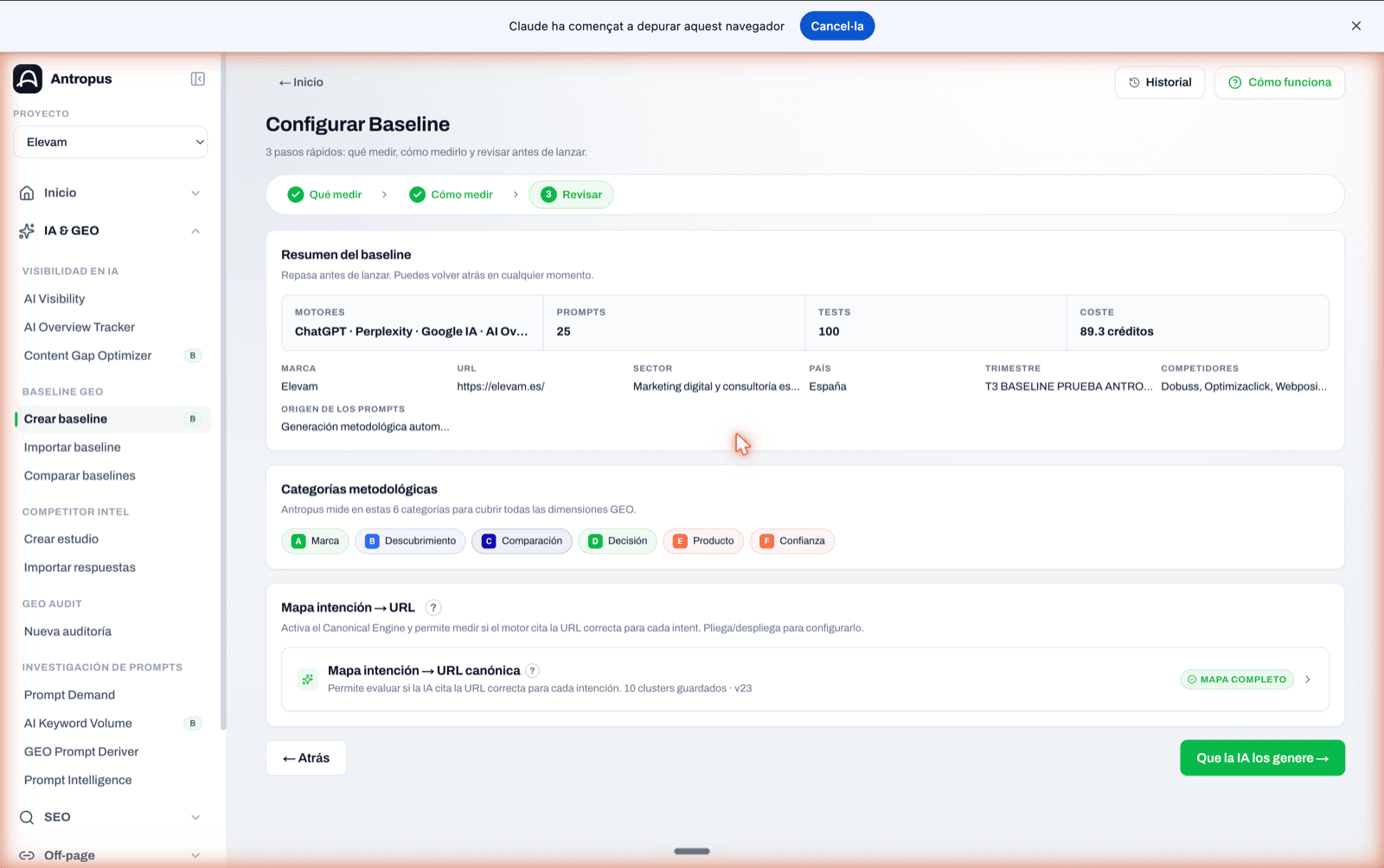
Step 3 "Review": baseline summary before launching, chips of the six methodological categories and the collapsible intent map editor.
7.4 Generating and reviewing the prompt set
When you press "Let the AI generate them", Antropus starts a visible process: it analyzes the business context, builds the methodological distribution, generates each of the six categories in turn (B → D → C → A → E → F), validates the global distribution (B+C+D ≥ 51%, A ≤ 30%) and detects brand bias and semantic duplicates. You see it in a list with a green check for each completed step.
Immediately after, you reach the "Review prompts" screen. There, before launching, you see:
- The methodological distribution panel, with a global score and warnings when something doesn't add up (for example, "B+C+D represent 50% of the set. Methodological minimum 51%").
- The list of prompts grouped by category A–F, with its text, its category and the "canonical URL" column per prompt.
- An important detail: if you have an intent map configured, Antropus automatically fills in the canonical URL of each prompt according to its category. On the screen a notice appears ("X canonical URLs auto-filled from the intent map") and the prompts enter already with their URL aligned. If you want a different URL for a specific prompt, you override it there.
- Buttons to add prompts by hand, paste several at once, copy the list or go back to the source.
Even though Antropus generates them with methodology, we always review before launching. We rewrite the prompts that don't have the sector's natural angle, recategorize the misclassified ones and deactivate the ones that don't apply (without deleting them, in case they're reactivated next quarter).
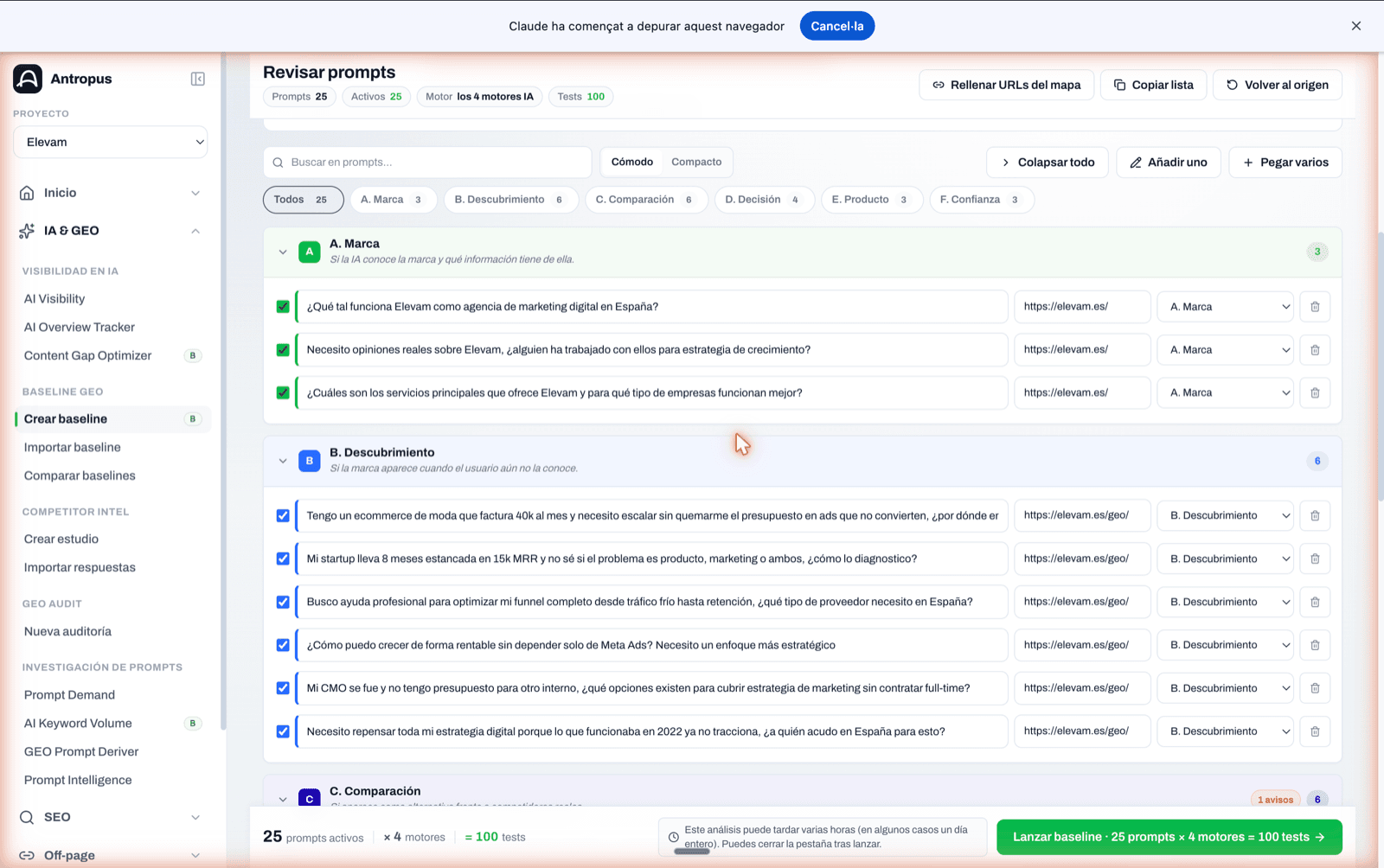
Prompt review screen: each A–F category as a collapsible section, with its text, auto-filled canonical URL and category selector.
7.5 Launch and monitor
You press "Launch baseline" and the work is queued in the backend, which runs asynchronously in batches and keeps saving progress. In practice, this means three things that matter more than they seem:
- You can close the tab. The baseline keeps running and, when you return, you see the real progress.
- If an engine fails technically (timeout, quota), that test is marked as failed and the batch continues. The work doesn't collapse entirely because of a provider that had a bad day.
- You can cancel midway if you see something's going wrong; the already-completed tests are kept.
The "Baseline in progress" screen has a progress core ("AI Execution Core") with an SVG ring, the large percentage in the center and nodes per engine around it (green = completed, blue = in progress, gray = pending). A linear bar at the top shows "X/N tests" and "X% complete". Below: cards per engine with their individual state, the current prompt highlighted, the queue of pending prompts and a phase line.
A small baseline (5 prompts × 4 engines = 20 tests) takes between 3 and 8 minutes. A standard one (30 prompts × 4 engines = 120 tests) can stretch to 20–35 minutes depending on provider performance.
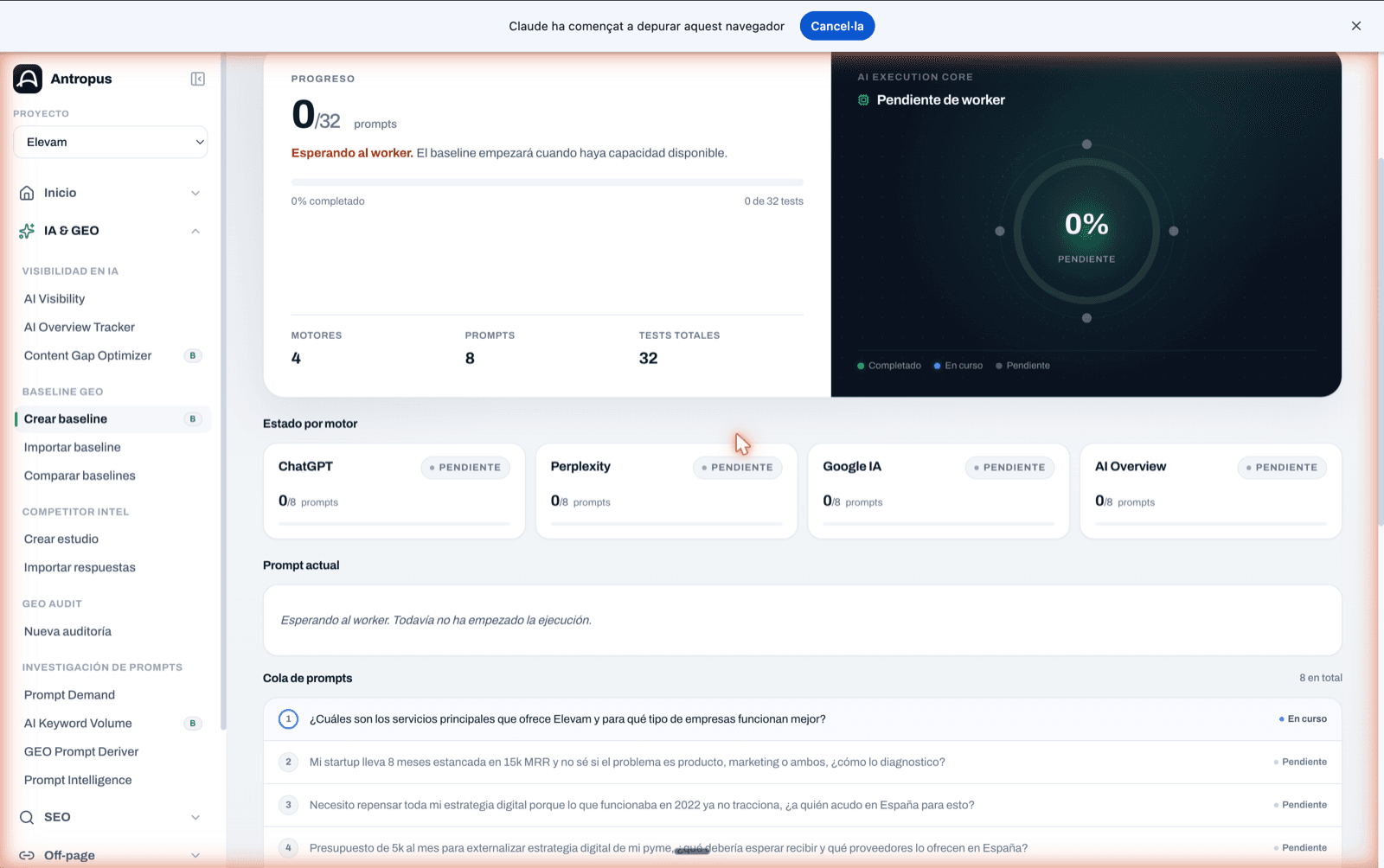
AI Execution Core: SVG ring with the percentage in the center and nodes per engine around it (green = completed, blue = in progress). Cards per engine + current prompt.
8. How to read and interpret the results
This is where the real consultant work begins. Antropus gives you the numbers and the structured diagnosis; you turn them into recommendations. These are the four readings we always do.
8.1 Reading 1 — The four headline indicators
The combinations of SoR, BCR, R and Top 3 give you the macro picture in one shot:
- High SoR + low BCR: the AI recommends you but doesn't link you. A citation problem, not a visibility one.
- High BCR + low R: they link you, but to the wrong URL. A canonical problem, not a citation one.
- High R + low Top 3: the correct URL appears, but not at the top. A relevance or authority problem for that intent.
- All low: a fundamental problem. Probably missing entity signals or the client doesn't have enough content.
That's the first cut of the report.
8.2 Reading 2 — The failure taxonomy
Antropus classifies failures into 15 types with severity scaled by commercial value. Grouped:
- Hallucinations: entity confusion; acronym ambiguity; wrong authorship attribution; topic drift; favorable claim without a source; URL that doesn't answer the intent.
- Canonical: canonical drift (own URL different from the expected one); source dispersion; own-source weakness (they mention you, but without citing anything of yours).
- Sources: third-party dependence (your visibility hangs solely on outside sources); competitor dominance (they cite the competition and not you, or not in the top 3).
- Activation: category-activation failure (a question without brand and no mention in B/D/E/F); comparative shortlist failure (category C without a top 3).
And each failure comes with four things: a human title ("Canonical drift", "Entity confusion"…), a description of what's happening, its impact in business language ("loss of control of the URL that captures commercial demand") and a suggested solution type that links directly to the Antropus tool that solves it.
8.3 Reading 3 — Severity scaled by commercial value
A canonical drift in category A (brand) is high severity. The same drift in category D (commercial decision) escalates to critical, because it actually costs money. The high-value categories are D (decision), C (comparison) and B (discovery): any failure in them goes up a severity step relative to the same failure in A, E or F.
This saves you work: when you deliver the report, the prioritized actions aren't "the ones with the most failures", but the ones with the most commercial impact.
8.4 Reading 4 — Recommended actions with a success criterion
Each failure generates an action with a priority (1–3), a target tool (a direct link to the Antropus function that solves it: entity editor, copywriter, content architecture…) and a measurable success criterion. For example: "Citation Rate ≥ 50% in category D in the next baseline."
That's what you deliver as a roadmap. Not "your visibility is medium" (useless), but "these seven problems, in this order, with this tool, and we validate the result with this metric in three months".
"Intelligence" tab with detected failures classified by severity, prioritized actions with their target metric and success criteria.
9. The methodological disclaimer and statistical traceability
A serious audit acknowledges its limits in writing. In Antropus, every exported PDF carries an automatic methodological disclaimer. And underneath, the engine applies a series of statistical honesty rules that most tools skip. The two things, together, are what really sets apart a report that holds up to external review from one that collapses at the first poke.
9.1 What your GEO audit must declare (always)
- AI models are not deterministic. The same question can give different answers in consecutive runs. That's why a baseline is a sample, not an absolute truth. To detect real changes, we compare several tests per engine and look at the variance.
- Web grounding is imperfect. The providers' web searches may return incorrect sources or return none despite having consulted them. Antropus detects and flags this (for example, Gemini's opaque redirects, which hide the real domain under URLs like vertexaisearch.cloud.google.com/grounding-api-redirect/…).
- Similar brands get confused. Without a well-built entity profile, homonyms produce false positives. Antropus scores the profile's quality in four states and advises against measuring if it's in the two worst.
- Small samples have a lot of variance. Antropus advises against drawing conclusions from baselines with fewer than 15 prompts. A metric over 5 evaluables has no statistical power.
- We don't promise "guaranteed position in ChatGPT". The model changes, the mode changes, the app changes. What we do promise is a repeatable methodology and a clear diagnosis. Anyone who promises you the former is selling you smoke.
- The AI Overview Triggering Rate varies. Not every search triggers the generative block. Antropus measures it and separates "Google didn't show the block" from "your brand didn't appear", two things most tools mix up.
Declaring these limits doesn't subtract credibility. It adds it. The client who understands that a tool acknowledges its margins of error is the same one who trusts you the next quarter.
9.2 The seven statistical honesty rules
- If it can't be measured, it isn't invented. When the denominator is 0, the metric is "not measurable", not 0. On the dashboard it shows "—"; in Excel, empty. A silent 0 misleads the client.
- The "not measured" is filtered out of SoR. "I didn't measure it" is not "it's the worst option". Distinguishing it is the difference between an honest SoR and one corrupted by old baselines.
- Tests with entity confusion leave the visibility denominator. If Gemini confused you with a homonym, that test doesn't inflate your SoM: it enters the methodological validity rate.
- Heterogeneity is declared. If the difference between the best and worst engine exceeds 40 percentage points, the global is flagged as heterogeneous and the dashboard warns you not to draw conclusions from the average, because one engine is distorting it.
- On the generative SERP, "it triggered" and "it didn't trigger" go separately. If Google didn't show the block, that test doesn't enter visibility: it enters Triggering Rate. Different metrics, different interpretations.
- Automatic warnings by sample size. Fewer than 12 prompts: warning. Fewer than 15: recommends expanding. Fewer than 5 evaluables: the intelligence engine refuses to diagnose.
- Source reliability weights by opacity. Opaque URLs (Gemini's redirects) penalize the score; auditable ones raise it. The weighted share of voice uses this score, so that a mention in Perplexity with an official source weighs more than one in Gemini with a redirect.
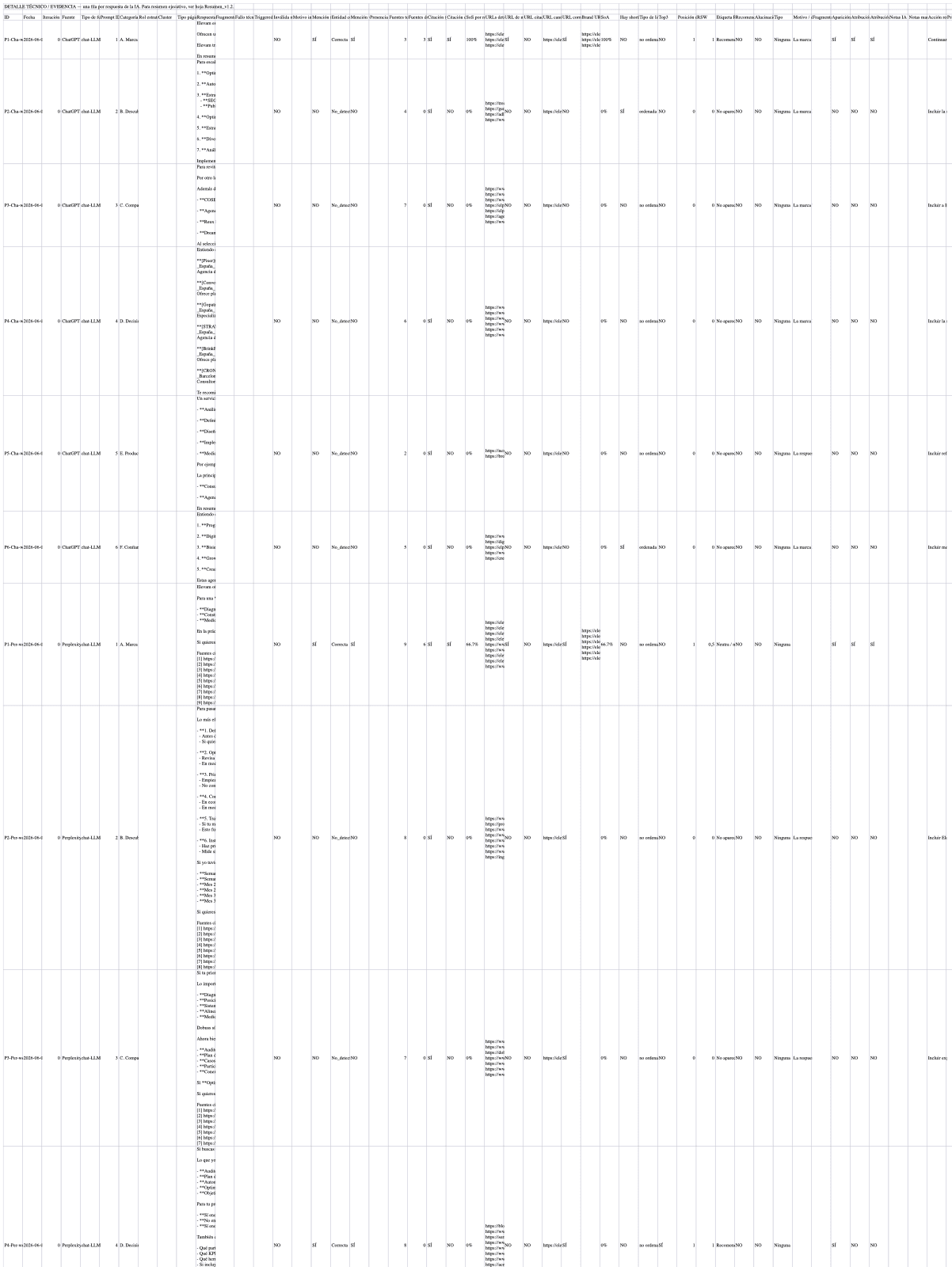
Detail of the downloadable Excel. When a metric can't be computed, the cell carries "—" instead of "0"; a clean table, no clutter.
10. How long does a serious GEO audit take?
So you have a real reference, this is the breakdown of a complete audit just as we deliver it at Elevam:
| Phase | Time |
|---|---|
| Project setup + entity profile | 30–60 min |
| Intent map | 45–90 min (depending on site size) |
| Prompt generation | 5 min (auto) + 15–30 min of human review |
| Baseline execution (30 prompts × 4 engines ≈ 120 tests) | 20–35 min automatic |
| Analysis and report writing | 2–4 hours |
| PDF/Excel deliverable (with methodological disclaimer included) | 30 min automatic |
In total, roughly one consultant workday. If the client wants maximum depth (60 prompts × 6 engines, around 360 tests with all the generative SERPs active), it stretches to a day and a half. But the result easily justifies a four-figure invoice —often several thousand euros—, especially if you package it well (one-off audit, or audit + remediation + a second baseline to validate results).
11. Mistakes we see again and again in previous GEO audits
When a client shows us the audit they had done before, we almost always find the same mistakes:
- They only measured in ChatGPT. As if it were the only engine. Claude, Gemini, Perplexity and Google's AI Overview block also have an audience, and the results can be very different. A serious audit measures in at least three engines.
- They don't separate memory from web. The results change radically. A serious baseline measures both modes where the engine allows it and, in addition, includes Google's generative SERP to see what Google says without the user leaving the search engine.
- SoM comes out at 80% because the set was 100% brand. We've said it already, but it's worth repeating.
- There's no entity profile. The analyzer doesn't tell the brand apart from its homonyms. Systemic false positives.
- There's no intent map. They only look at "did any URL of the domain show up?". They detect neither cannibalization nor drift.
- Metrics without a denominator. "Citation Rate 35%." Over what? Total tests? Evaluable ones? Visible ones? Without knowing, the number is noise.
- Impossible promises. "You'll be in ChatGPT's top 3 in 90 days." That can't be promised, because neither the model, nor the mode, nor the app are stable.
When a client arrives with a report like that, the conversation is easy: "this isn't a GEO audit, it's the sales material of whoever made it. Let me show you how it's done well".
12. Frequently asked questions about the GEO audit
What exactly is a GEO audit?
It is the systematic measurement of how your brand appears in the answers of generative AI engines (ChatGPT, Claude, Gemini, Perplexity) and in Google's AI Overview block: whether you're mentioned, in what position, whether your site is cited and whether you're confused with another company.
How does a GEO audit differ from an SEO audit?
SEO measures your position in Google's search results. The AI visibility audit measures your presence within generated answers, which have no positions or clicks in the usual sense. They're complementary disciplines, with their own tools and metrics.
How do you keep the metrics from being inflated?
By splitting the questions across six mandatory categories —with between a quarter and a third of generic questions, where the brand only appears if it's genuinely recommended—, by not counting brand confusions as a hit and by showing a "—" when there isn't enough sample for a reliable figure.
Which tool do you use to run the GEO audit?
We use Antropus, the SEO and GEO platform developed by Elevam Labs. It can measure four LLMs (Claude, ChatGPT, Gemini, Perplexity) plus Google AI and AI Overview, with entity resolution, an intent map and an engine that turns metrics into prioritized actions.
How often should you repeat an AI visibility audit?
Quarterly is recommended, using the same prompt set so the comparison stays valid. Models change frequently, and only by measuring regularly do you detect in time whether your visibility is rising or falling.
Can you guarantee appearing in ChatGPT or Google AI Overview?
No, and be wary of anyone who promises it. What you can do is measure rigorously, diagnose where you're failing and work on the signals (entity, content, citations, architecture) that increase your chances of appearing.
13. Conclusion
A serious GEO audit isn't firing 30 prompts at ChatGPT and summarizing the result in a PDF. It's a measurement protocol with a closed methodology, metrics you can compute, a clear failure taxonomy and declared margins of error.
What to take away:
- The AI visibility audit measures something different from classic SEO. It needs its own tools and methodology.
- The prompts must be split across six categories (A–F) with different brand policies. A set biased toward A produces inflated, useless metrics.
- SoR (weighted by recommendation strength) is the headline metric of a serious GEO dashboard. SoM (binary) is secondary.
- The intent → canonical URL map activates the structural analysis: drift, cannibalization, problematic URLs. Without it, you lose 80% of the value.
- Entity confusions don't inflate SoM: they leave the denominator. That's how false positives are avoided.
- If it can't be measured, it isn't invented. Heterogeneity is declared. Small samples are flagged. This is told to the client; it's not hidden.
At Elevam we use Antropus for all our GEO audits. It's what lets us respect all of the above without massive manual work: a resilient asynchronous backend, an intelligence engine that turns metrics into prioritized actions and exportable to PDF with a methodological disclaimer included.
About Antropus
Antropus.io is the SEO and GEO platform developed by Elevam Labs, the product lab of the agency Elevam, led by Asier López Ruiz. It combines real data from professional industry providers with its own AI analysis to audit brands' visibility in both search engines and generative engines, in a single suite and with an approach centered on data honesty.


