Cómo montar una auditoría de visibilidad en IA que aguante una auditoría: con métricas que sabes calcular, una taxonomía de fallos clara y acciones priorizadas por impacto comercial. De la teoría al paso a paso real con la plataforma que usamos en Elevam para esto: Antropus.
¿Quieres saltarte la teoría y que lo hagamos por ti? Solicita una auditoría GEO para tu marca y te enseñamos exactamente dónde apareces (y dónde no) en las respuestas de IA.
1. Qué es una auditoría GEO (y por qué no es SEO)
Empecemos por la definición, porque medio sector la usa mal.
Una auditoría GEO (de Generative Engine Optimization) es el proceso de medir, evaluar y diagnosticar la presencia de una marca en los motores de inteligencia artificial generativa. En concreto, en seis superficies:
- ChatGPT (OpenAI)
- Claude (Anthropic)
- Gemini (Google)
- Perplexity (Sonar)
- El modo generativo de Google (la respuesta conversacional dentro del propio Google)
- Google AI Overview (el bloque generativo que aparece por encima de los resultados orgánicos)
El SEO clásico responde a "¿qué posición ocupo en Google para esta keyword?". Una auditoría de visibilidad en IA responde a otra pregunta, distinta y hoy más urgente:
Cuando un usuario le pregunta a una IA por mi sector, ¿aparece mi marca? ¿En qué posición? ¿Citan mi web o la de un competidor? ¿La IA me conoce de verdad o me confunde con otra empresa?
La diferencia no es de matiz, es de naturaleza. Google Search Console te da impresiones, clics, CTR y posición media. Los modelos generativos no te dan nada de eso. Cuando alguien pregunta a ChatGPT, recibe un texto redactado, a veces con fuentes y a veces sin ellas. Nadie te avisa de que tu marca salió, de que te confundieron con otra o de que recomendaron a tu competidor. La respuesta es, literalmente, una caja negra.
Para abrir esa caja hace falta un protocolo de medición sistemático y repetible. Eso, y no un puñado de capturas de pantalla, es una auditoría GEO.
“El SEO nos dice cómo nos encuentra Google. El GEO nos dice cómo nos cuenta una IA. Y cada vez más decisiones de compra empiezan en la segunda conversación, no en la primera búsqueda.
”
1.1 SEO clásico, GEO y medición de IA: tres cosas distintas
| Disciplina | Qué mide / Fuente del dato |
|---|---|
| SEO clásico | Posición orgánica en Google, impresiones, clics, backlinks · Search Console y proveedores de datos de SEO |
| GEO | Cómo aparece la marca en motores de IA: frecuencia, posición, citación, confusión de entidad · Tests propios contra las IAs + un analizador |
| Medición de IA | La capa que une ambos mundos: separa lo que viene del buscador de lo que viene del asistente · Antropus lo orquesta y lo compara |
Hoy un cliente serio necesita las tres. Pero esta guía va de la del medio, que es la que casi nadie sabe hacer bien.
2. Por qué tu marca necesita una auditoría de visibilidad en IA ahora
No es una moda. Es un cambio de canal, y va rápido.
Cuando alguien pregunta "mejor agencia de GEO en España" a ChatGPT y se queda satisfecho con la respuesta, ese usuario no llega nunca a Google. El tráfico que captas en buscador para esa intención es, cada vez más, solo la fracción que la IA no resolvió. Es decir: lo que ves en Search Console es la punta del iceberg, y el iceberg está creciendo por debajo del agua, donde tu analítica clásica no mira.
El tamaño de ese "debajo del agua" ya no es anecdótico. Según OpenAI (febrero de 2026), ChatGPT supera los 900 millones de usuarios activos semanales y se acerca a los mil millones. Súmale los cientos de millones de Gemini, la base de Claude y el crecimiento de Perplexity como buscador alternativo, y tienes audiencias enteras que tu estrategia de SEO clásico, sencillamente, no mide.
Y luego está Google jugando en los dos tableros a la vez: en muchísimas búsquedas informacionales y bastantes comerciales, el bloque de AI Overview aparece por encima de los resultados orgánicos. Si tu marca no entra en esa respuesta sintetizada, has perdido el clic antes de que el usuario llegue siquiera a la lista de enlaces azules.
Así que la pregunta no es si vas a necesitar medir tu visibilidad en IA. La pregunta es cuándo te enteras de que ya la estabas perdiendo y nadie te avisó.
2.1 Qué problemas concretos resuelve una auditoría GEO bien hecha
Una auditoría seria te permite, en la práctica:
- Saber si tu marca aparece (o no) en respuestas a preguntas reales de tu sector.
- Detectar si la IA te conoce bien o te confunde con un homónimo. Nos ha pasado con nuestra propia marca: en ciertas pruebas, Elevam aparecía confundida con ElevenLabs.
- Ver si la IA recomienda a tu competencia en tu lugar, y en qué tipo de preguntas exactamente.
- Identificar qué URL de tu sitio cita la IA y si es la correcta para esa intención.
- Descubrir canibalización: tu blog ocupando el sitio que debería ocupar tu landing de servicios.
- Cuantificar cuántas de tus apariciones son recomendaciones fuertes y cuántas son menciones de relleno sin valor comercial.
- Tener un baseline cuantitativo y comparable trimestre a trimestre para saber si tus acciones de optimización funcionan o no.
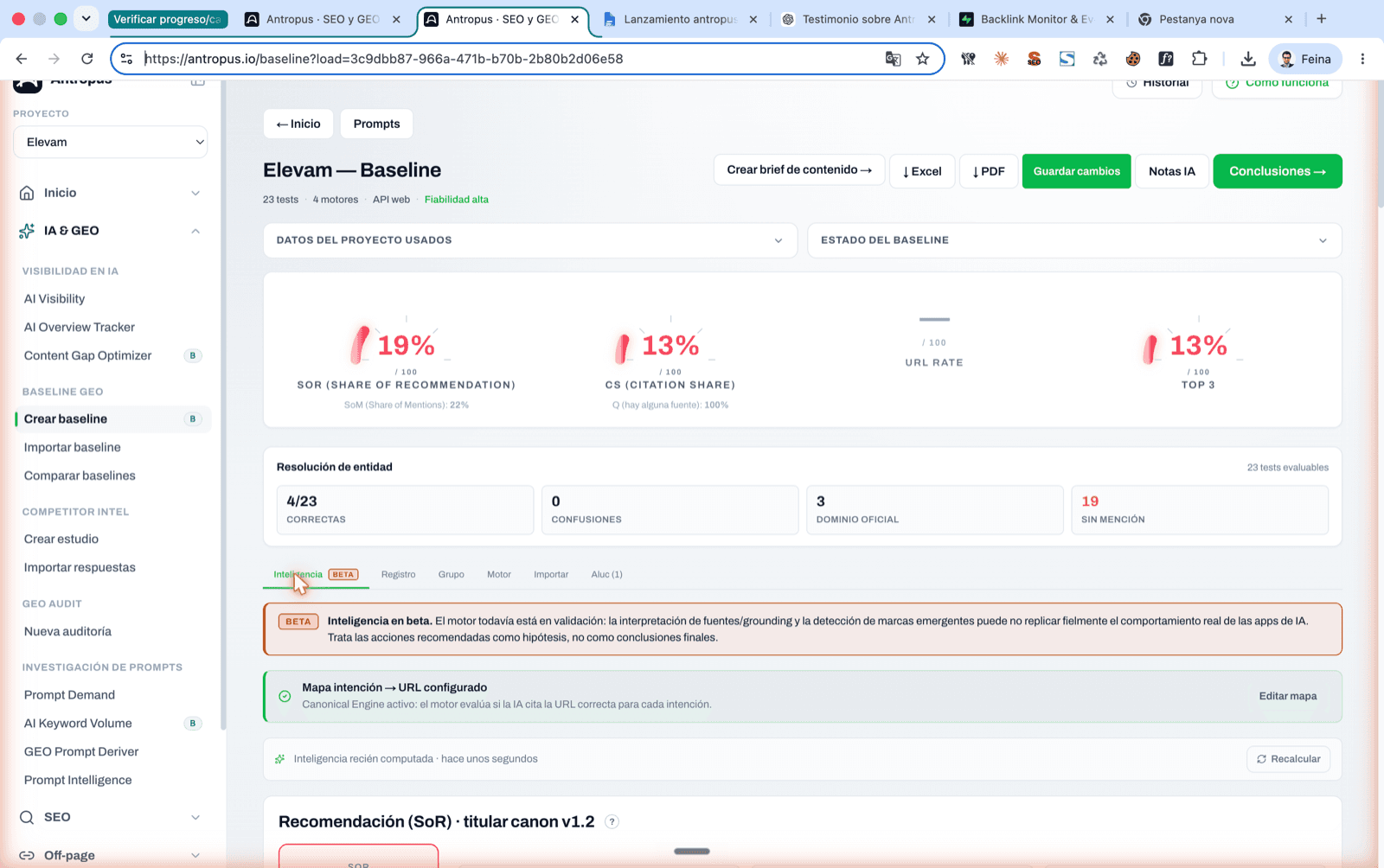
Pantalla principal de un baseline finalizado en Antropus, con los 4 indicadores titulares (SoR, CS, URL Rate, Top 3) y la resolución de entidad.
3. El error que comete la mayoría de auditorías GEO
Antes de explicar cómo lo hacemos en Elevam, hay que desmontar lo que se vende por ahí. La mayoría de las "auditorías GEO" que llegan a nuestras manos —normalmente cuando un cliente nos enseña la que le hicieron antes— falla en al menos uno de estos tres puntos. Y los tres tienen el mismo efecto: un informe que parece bueno y no sirve para nada.
3.1 Prompts sesgados hacia la marca
Es el error más común y el más caro. El consultor lanza 30 preguntas a ChatGPT, pero todas son de este estilo:
- "¿Qué opinas de [marca]?"
- "Opiniones sobre [marca]"
- "¿[Marca] es de fiar?"
- "Compara [marca] con [competidor]"
La IA está obligada a hablar de la marca en cada respuesta, porque el prompt la nombra. El resultado: un Share of Mentions del 90%. El consultor se lo enseña al cliente como un triunfo. No está midiendo nada útil.
Lo que el cliente necesita saber es si la IA lo recomienda cuando el usuario todavía no lo conoce. Y eso solo se mide con preguntas a ciegas (blind), del tipo:
- "¿Cuál es la mejor agencia de SEO en Madrid?"
- "Recomiéndame plataformas para gestionar GEO"
- "¿Qué herramientas usan las agencias para medir su visibilidad en IA?"
Si tu marca no sale ahí, no estás captando demanda nueva en IA. Tan simple como eso. Y si tu auditoría no mide esto, tu auditoría no es una auditoría: es el folleto comercial del consultor para justificar la siguiente factura.
3.2 Métricas binarias disfrazadas de métricas ponderadas
El segundo fallo: usar el Share of Mentions (SoM) como métrica estrella. El SoM es binario: cuenta si la marca apareció o no, y nada más. No distingue la fuerza con la que te recomiendan.
Compara estas dos respuestas:
- "Te recomiendo [marca]; es la mejor opción del mercado, y te explico por qué…"
- "Hay muchas opciones; algunas son X, Y, Z, y también está [marca]."
Las dos suman exactamente lo mismo al SoM. Pero la primera vale diez veces la segunda. Sin una métrica que pondere la fuerza de la recomendación, tu auditoría tira a la basura la mitad de la información que importa.
La métrica que sí pondera es el SoR (Share of Recommendation), y es la métrica titular del dashboard de Antropus. El problema es que el mercado todavía no la usa, así que casi nadie la reporta. Volvemos a ella en detalle más abajo.
3.3 Denominadores tramposos
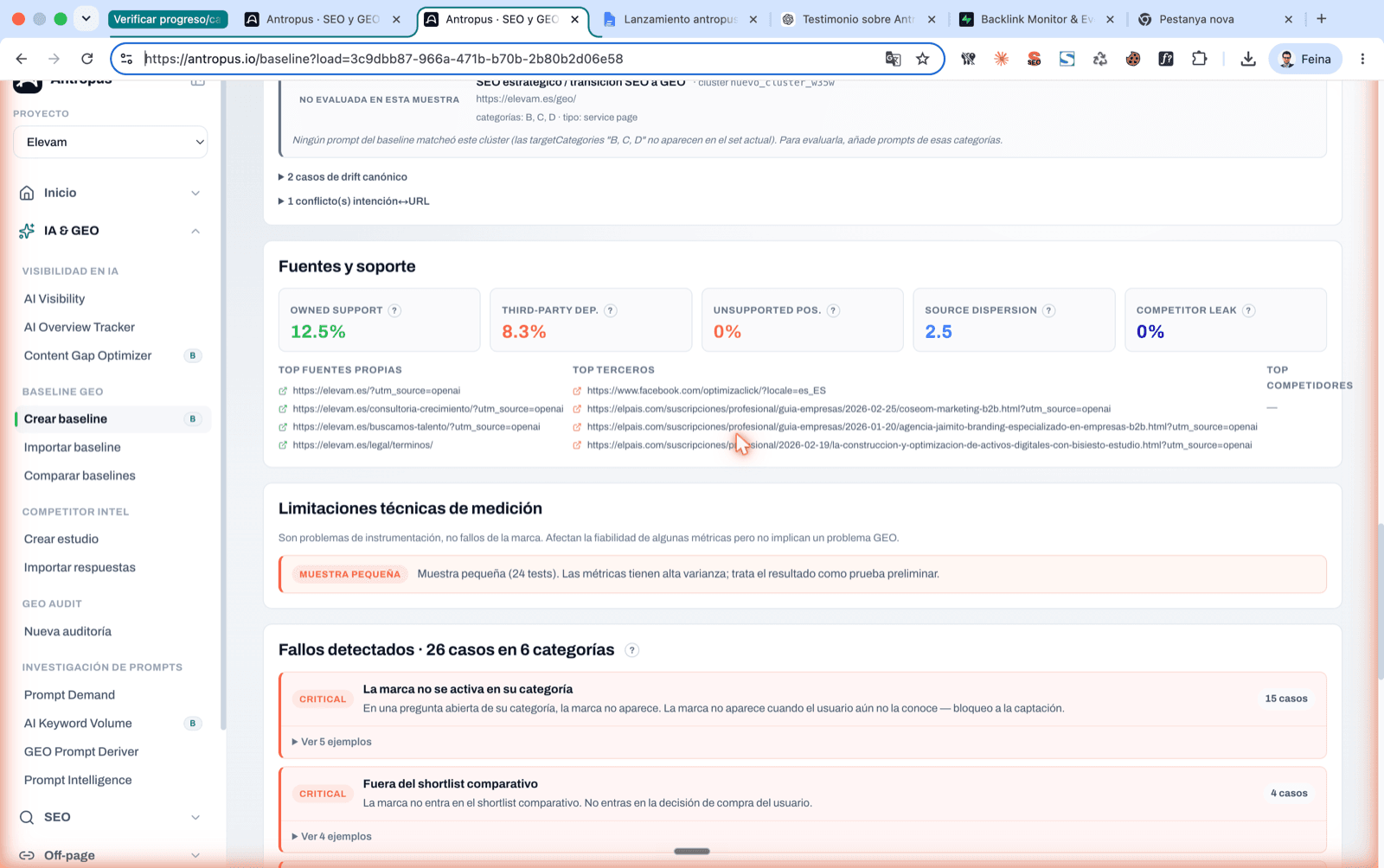
El tercero es estadístico, parece menor y arruina informes enteros. Imagina que lanzas 30 prompts a Gemini con web activa y 8 fallan técnicamente (timeout, cuota agotada). No puedes calcular tu Citation Rate como 2 / 30 = 6,6 %. Esos 8 no son "respuestas en las que no te citaron"; son respuestas que no llegaron a existir. El cálculo honesto es 2 / 22 = 9 %.
El mismo dato, dos denominadores
Un detalle de denominador, una diferencia enorme en el informe: contar los 8 tests fallidos como "no me citaron" infraestima tu presencia y entrega un diagnóstico falsamente alarmante.
4. Las seis categorías obligatorias de prompts (A–F): el corazón de la metodología
Una auditoría GEO seria no deja que escribas las preguntas a tu antojo. Fuerza una distribución metodológica que neutraliza el sesgo de marca. En Antropus las llamamos categorías A–F, y son obligatorias en todo baseline.
4.1 El catálogo
| Cat. | Nombre | Qué mide | Política de marca | % por defecto |
|---|---|---|---|---|
| A | Marca y reputación | Si la IA conoce tu marca y qué sabe de ella | Siempre con marca | 10–15 % |
| B | Descubrimiento genérico | Si apareces cuando el usuario NO te conoce | Nunca con marca | 25–30 % |
| C | Comparación competitiva | Si apareces como alternativa frente a competidores | Moderada | 20–25 % |
| D | Decisión comercial | Si apareces en el momento de comprar | Nunca con marca | 15–20 % |
| E | Producto / categoría | Si apareces en búsquedas técnicas o de catálogo | Nunca con marca | 10–15 % |
| F | Objeciones y confianza | Si apareces cuando el usuario tiene dudas | Rara | 10–15 % |
4.2 Por qué exactamente esta distribución
Detrás hay tres reglas duras, que en Antropus no son una recomendación sino código que se ejecuta:
- La categoría A nunca pasa del 30 % del set. Si te pasas, estás midiendo reputación de marca, no visibilidad GEO.
- B + C + D suman al menos el 51 %. Es la mayoría a ciegas y comercial: donde de verdad se decide si captas demanda nueva.
- Las seis categorías tienen que estar presentes si el set tiene seis prompts o más. Cubrir solo tres o cuatro sesga la lectura.
Y por debajo hay un orden de prioridad para sets pequeños (menos de 12 prompts): B → D → C → A → E → F. Es decir, si solo puedes lanzar seis preguntas, las gastas en ese orden; no empiezas por A por inercia narcisista.
4.3 Qué pasa si te saltas estas reglas
Si lanzas 30 prompts donde 25 son de categoría A (todos con tu marca dentro), tu SoM saldrá entre el 70 % y el 95 %. Se lo enseñas al cliente como un éxito. Y al trimestre siguiente, cuando volváis a "optimizar", no habrá cambiado nada: porque la auditoría no medía nada que se pudiera mover.
Antropus se niega a calcular ciertas métricas si la muestra evaluable es menor de 5, y avisa de forma explícita cuando el set tiene menos de 12 prompts ("no cubre toda la metodología") o menos de 15 ("muestra mínima recomendada para sacar conclusiones"). Preferimos un "—" honesto a un número que engaña.
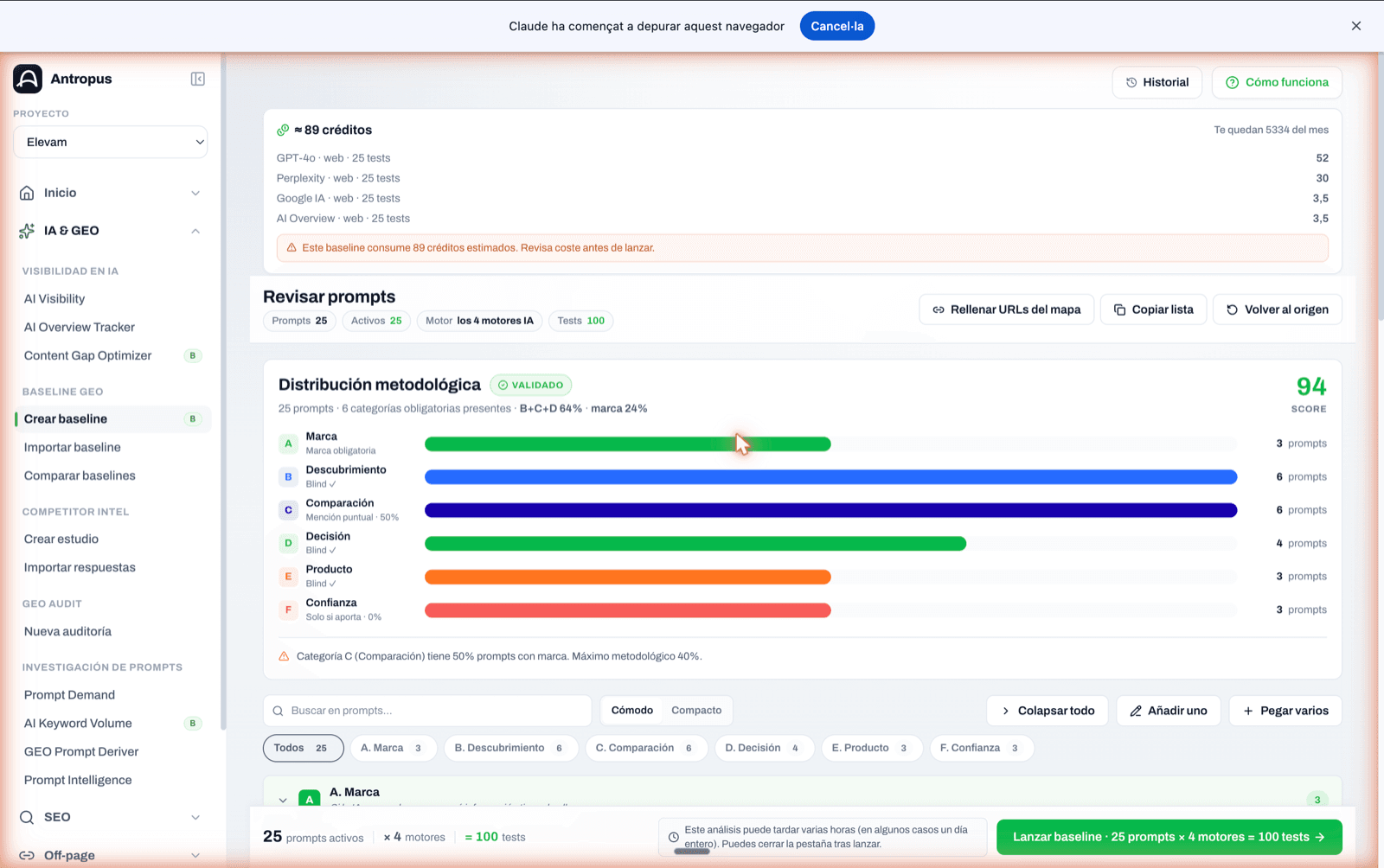
Panel de distribución metodológica de un baseline en revisión. Score 82 y avisos cuando B+C+D no llega al 51 % o cuando hay menos de 12 prompts.
5. Las métricas que importan: qué se mide y cómo se calcula
Una auditoría GEO seria reporta entre cuatro y seis métricas titulares, cada una con su denominador declarado. No veinte métricas sueltas sin contexto. Estas son las que pintamos en el dashboard de Antropus.
SoR
Share of Recommendation
La titular. Fuerza media con la que la IA te recomienda.
BCR
Brand Citation Rate
% de respuestas que citan una fuente de tu dominio oficial.
R
URL Rate
% de respuestas que citan la URL canónica esperada.
Top 3
Top 3 Share
% de rankings ordenados donde apareces en posiciones 1-3.
5.1 SoR — Share of Recommendation (la titular)
Qué mide: la fuerza media con la que la IA te recomienda. Es la única métrica que pondera la calidad de la aparición, no solo su existencia.
Cómo se calcula: media del peso de recomendación (rsw) sobre las respuestas en las que ese peso se ha medido. Los valores son discretos:
| rsw | Significado |
|---|---|
| 1.0 | Apareces como opción principal o recomendación destacada |
| 0.75 | Estás en el shortlist, con buena justificación |
| 0.5 | Te mencionan de forma neutra o como alternativa secundaria |
| 0.25 | Apareces de pasada, sin recomendación clara |
| 0.0 | Apareces, pero como opción descartada o desaconsejada |
| null | No medido (baselines antiguos sin repuntuar) |
El detalle que casi nadie respeta: el valor "no medido" se filtra del cálculo. No cuenta como 0. Confundir "no lo he medido" con "es la peor opción" corrompería el SoR de cualquier baseline antiguo.
5.2 BCR — Brand Citation Rate (citación de marca)
Qué mide: el porcentaje de respuestas donde aparece al menos una fuente de tu dominio oficial.
Es la métrica principal de citación, porque mide si la IA atribuye lo que dice a una fuente tuya y no a un blog de terceros o a un competidor. Que te mencionen está bien; que te citen como fuente está mucho mejor.
5.3 R — URL Rate (la URL correcta)
Qué mide: el porcentaje de respuestas donde la IA citó la URL canónica esperada para esa intención.
La clave está en el denominador: solo entran los tests con URL canónica mapeada en tu Intent URL Map. Si una intención no tiene cluster definido, ese test sale del cálculo. Así no inflas la métrica con muestras donde no había nada que evaluar.
5.4 Top 3 Share
Qué mide: el porcentaje de respuestas con ranking ordenado en las que apareces en posiciones 1, 2 o 3.
Detalle metodológico importante: el denominador NO es la visibilidad total, sino solo las respuestas con ranking ordenado (listas numeradas, comparativas explícitas, shortlists). Una respuesta narrativa que te menciona sin estructura de lista no entra. Calcular un Top 3 sobre respuestas sin ranking no significa nada.
5.5 Métricas auxiliares (pero nada accesorias)
| Métrica | Qué mide |
|---|---|
| SoM (Share of Mentions) | Binaria: % de respuestas donde apareces. Diagnóstica, nunca titular. |
| Validity Rate | % de tests metodológicamente válidos (sin confusión de entidad ni desvío de tema) |
| Triggering Rate | Solo en Google AI Overview: % de búsquedas donde Google muestra el bloque generativo |
| Source Reliability | Score 0–100 de fiabilidad de las fuentes (penaliza redirecciones opacas) |
| Hallucination Rate | % de respuestas con error factual, confusión de entidad o atribución errónea |
| Recomendación frágil | % de recomendaciones fuertes (rsw ≥ 0,75) basadas en una alucinación: visibilidad de alto riesgo |
| Source Dispersion Index | URLs propias compitiendo por la misma intención: mide canibalización |
| Competitor Leakage | % de respuestas donde aparecen URLs de competidores |
5.6 Las nueve agrupaciones del motor de métricas
Aquí está parte de la potencia real: cada métrica no se calcula solo en global, sino agrupada por motor, modo (memoria / web), categoría A–F, intención, tipo de demanda, rol estratégico, etapa del funnel y URL canónica esperada.
Eso te permite responder a las preguntas que de verdad hace un cliente: "¿En qué motor me va peor?", "¿Qué tipo de pregunta activa mejor mi marca?", "¿Qué URL de mi sitio está rindiendo más?", "¿En qué intención concreta estoy perdiendo cuota frente a mi competencia?". Y todo sin exportar a Excel ni pelearte con tablas dinámicas.
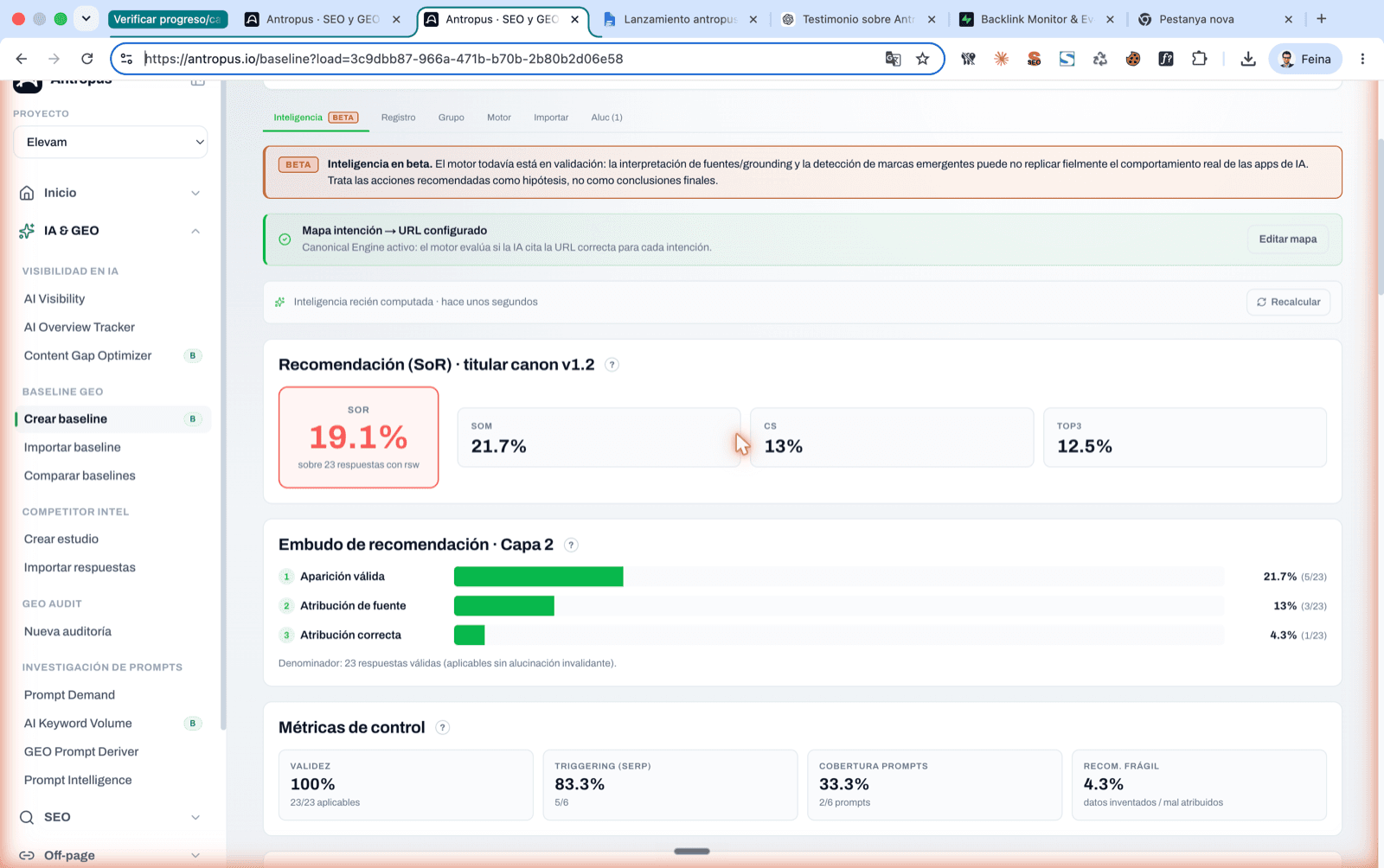
Indicador SoR (titular canon v1.2) y embudo de recomendación de 3 capas: aparición válida → atribución de fuente → atribución correcta.
6. El mapa de intención → URL canónica: la pieza que casi nadie mira
Aquí está uno de los diferenciadores más serios —y más ignorados— de una auditoría GEO bien hecha. Casi todas las herramientas miden "¿la IA citó alguna URL de tu dominio?" como un sí/no. Y eso se queda corto.
Lo que de verdad importa es:
¿Citó la URL correcta de tu dominio para esa intención?
Si un usuario pregunta "mejor agencia de GEO en Madrid" y la IA cita tu blog (/blog/que-es-geo/) en vez de tu landing de servicios (/servicios/geo-madrid/), técnicamente "te citaron". Pero estás regalando el clic comercial a una página informativa que probablemente no convierte. A eso lo llamamos drift canónico.
6.1 Qué es el mapa de intención
El Intent URL Map es una configuración a nivel de proyecto donde declaras, para cada cluster de intención, cuál es la URL canónica esperada de tu sitio. Cada cluster lleva:
- Nombre (p. ej. "Servicios GEO Madrid", "Marca / reputación", "Comparativa vs SEMrush")
- URL canónica esperada (la óptima para esa intención)
- URLs aceptables (otras tuyas que también cuentan como acierto)
- URLs problemáticas (las que NO deberían aparecer aquí, con su motivo)
- Categorías metodológicas que cubre (cuáles de A–F)
- Rol estratégico (reconocimiento de entidad, captura comercial, shortlist de comparación, etc.)
6.2 Las diez clasificaciones canónicas
Para cada test, el motor canónico clasifica la respuesta en una de diez categorías, con un score de 0 a 100:
| Clasificación | Score | Significado |
|---|---|---|
| Canónica correcta | 100 | Cita la URL canónica exacta |
| URL aceptable del cluster | 75 | Cita una URL aceptable del mismo cluster |
| URL propia, intención equivocada | 50 | Cita una URL tuya, pero no la canónica ni una aceptable |
| Activo de research absorbiendo intención comercial | 40 | Tu blog/recursos absorbe intención comercial |
| Home absorbiendo intención específica | 35 | Tu home absorbe una intención concreta |
| Fuente externa sustituyendo activo propio | 25 | Citan a terceros pero ninguna URL tuya |
| Dispersión de fuentes | 20 | Varias URLs tuyas compiten por la misma intención |
| Sin canónica disponible | 0 | Hay URLs, pero el mapa no declara canónica |
| Dominio equivocado | 0 | Las URLs citadas no son de tu dominio |
| Sin URL | 0 | No hay URLs en la respuesta |
6.3 Qué te devuelve el motor canónico
- Un score global de alineación canónica (0–100), calculado solo sobre tests evaluables: los "sin URL" y "dominio equivocado" no son drift, son no-activación, y no contaminan el score.
- Tus URLs canónicas más fuertes (las que reciben aciertos consistentes) y las más débiles (las que aparecen con score bajo).
- Los casos de drift: lista concreta de respuestas donde la IA citó una URL tuya equivocada, con su motor, su prompt, la URL esperada y la realmente citada.
- Los casos de dispersión, agrupados por intención.
- Los conflictos de URL: páginas que marcaste como problemáticas y que efectivamente están apareciendo.
6.4 Por qué esto es trabajo de agencia facturable
Cuando entregas un informe con casos de drift reales, no le estás dando al cliente una opinión. Le estás diciendo: "Aquí tienes 12 casos donde tu blog está absorbiendo búsquedas que deberían ir a tu landing de servicios. Aquí el motivo. Aquí la URL que debería salir. Aquí la que sale. Y aquí la acción: reforzar señales canónicas en la landing y rebajar el lenguaje comercial del post."
Eso es diagnóstico con evidencia. Y es trabajo que tú, como agencia, puedes cobrar sin sonrojarte.
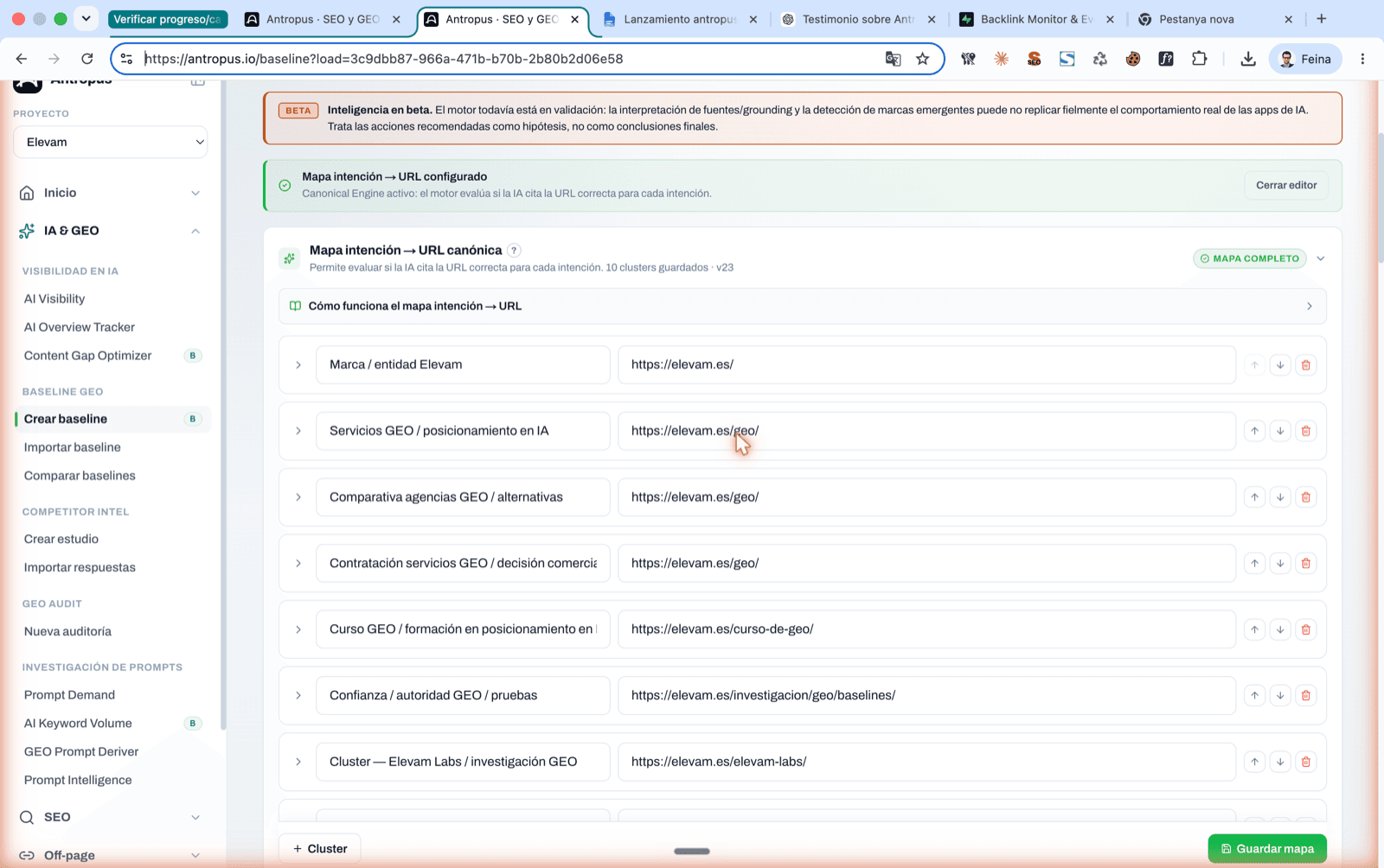
Editor del Intent URL Map de Antropus. Lista de 10 clusters reales del proyecto con URL canónica esperada por intención y badge "Mapa completo".
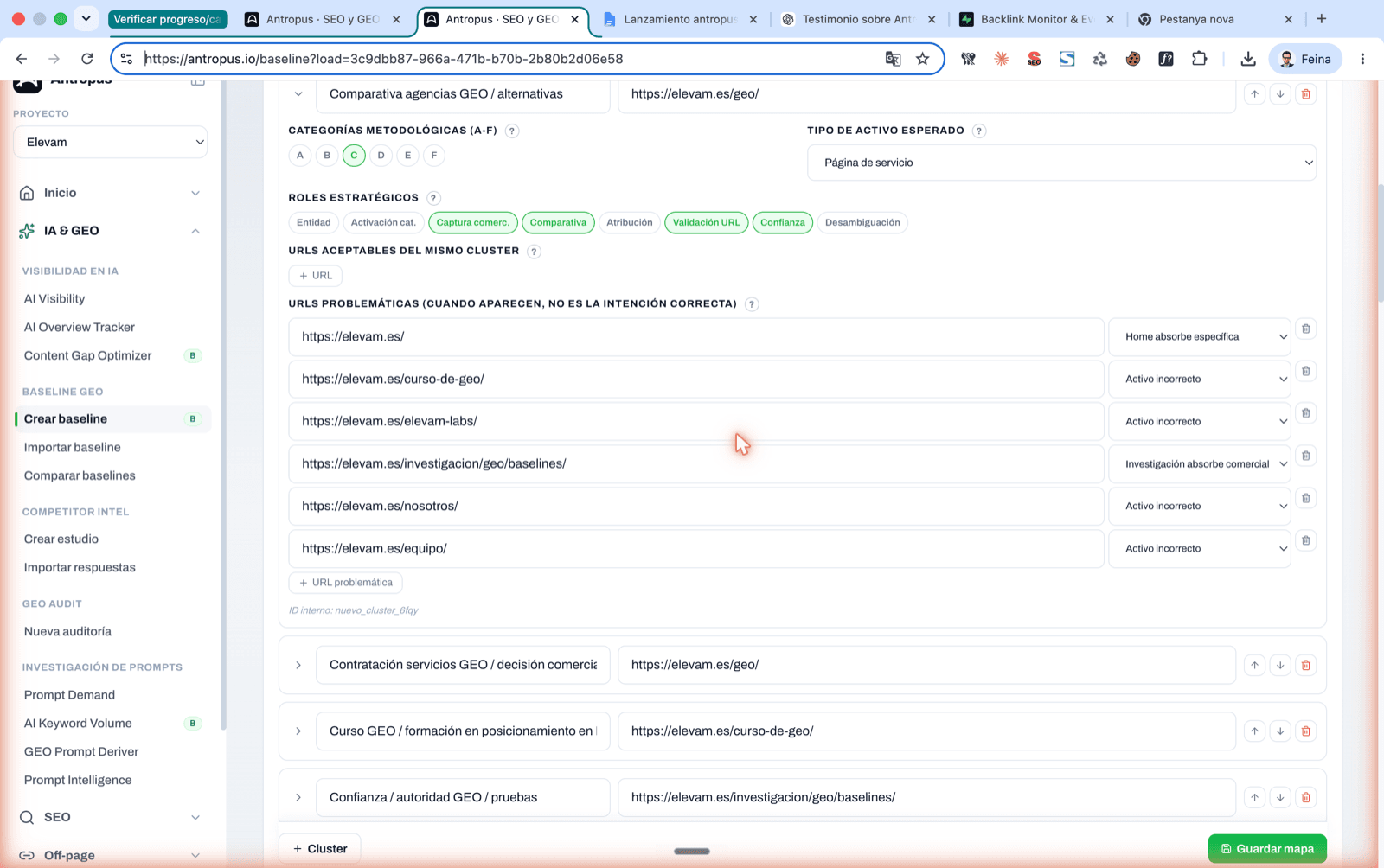
Detalle de un cluster expandido: URLs aceptables del mismo cluster + URLs problemáticas con su motivo (home absorbe específica, investigación absorbe comercial).
7. Cómo lanzar tu primera auditoría GEO con Antropus, paso a paso
Vamos al grano. Esto es, literalmente, lo que harías hoy desde cero para auditar la visibilidad en IA de un cliente nuevo. El wizard de Antropus tiene tres pasos: qué medir, cómo medir y revisar.
7.1 Paso 1 — Qué medir: identidad del proyecto y ficha de entidad
Antes de tocar nada, configuras el proyecto: marca, dominio, sector, país y hasta tres competidores declarados de forma explícita. Todo eso se rellena tirando de la ficha del proyecto si ya existe.
Y acto seguido completas la ficha de entidad (Entity Profile). Esto es lo que permitirá al analizador distinguir tu marca real de cualquier homónimo. Sin una ficha sólida, los resultados salen contaminados de raíz. Los nueve campos que rellenamos siempre:
- Nombre canónico (mínimo 3 caracteres, no una URL)
- Dominio oficial (sin protocolo ni www)
- Descripción canónica (factual, idealmente de 120 caracteres o más)
- Texto de desambiguación (una o dos frases sobre con qué entidades NO confundirte)
- Alias (otros nombres con los que puede aparecer la marca)
- Entidades relacionadas (personas, productos o conceptos propios que confirman que la respuesta habla de ti)
- Entidades a no confundir (las de nombre parecido que NO eres tú)
- Definiciones esperadas (tus términos propios y su definición canónica)
- URLs oficiales (las que cuentan como cita correcta más allá del dominio raíz)
Si tu marca tiene un nombre corto o un homónimo, este paso es crítico. Antropus incluye un asistente "Analizar web y proponer ficha" que investiga la marca en fuentes públicas y rellena los campos. Nunca sobrescribe: te muestra el cambio campo por campo y solo lo aplica si confirmas.
La pantalla te muestra en todo momento el estado de la ficha con un badge ("Lista para baseline", "Usable pero débil", "Incompleta", "Posiblemente inválida") y el porcentaje de completitud. Si la ficha está en los dos peores estados, Antropus desaconseja explícitamente lanzar el baseline.
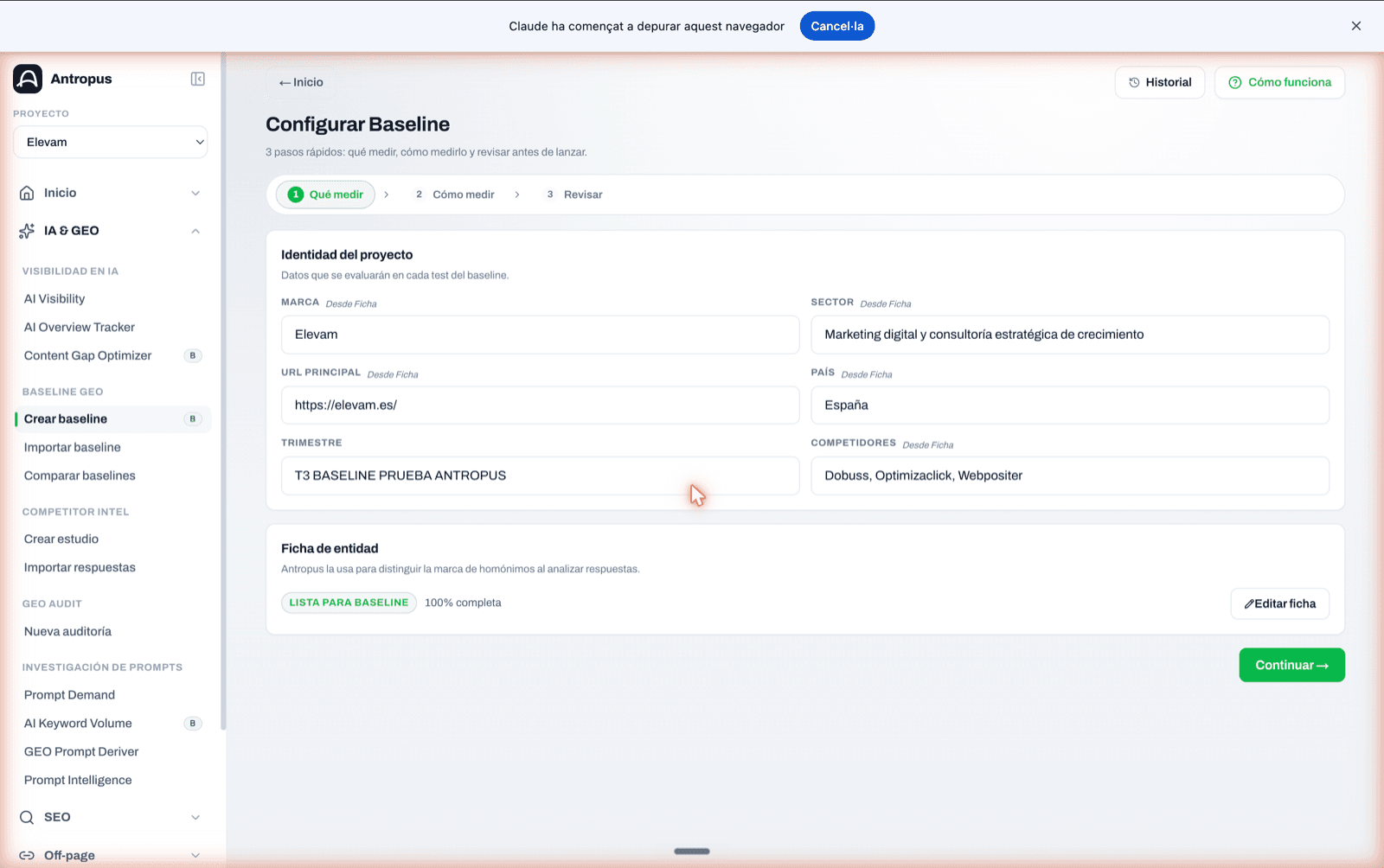
Paso 1 del wizard "Qué medir": identidad del proyecto rellenada desde la ficha y badge verde "Lista para baseline · 100% completa" en la sección Ficha de entidad.
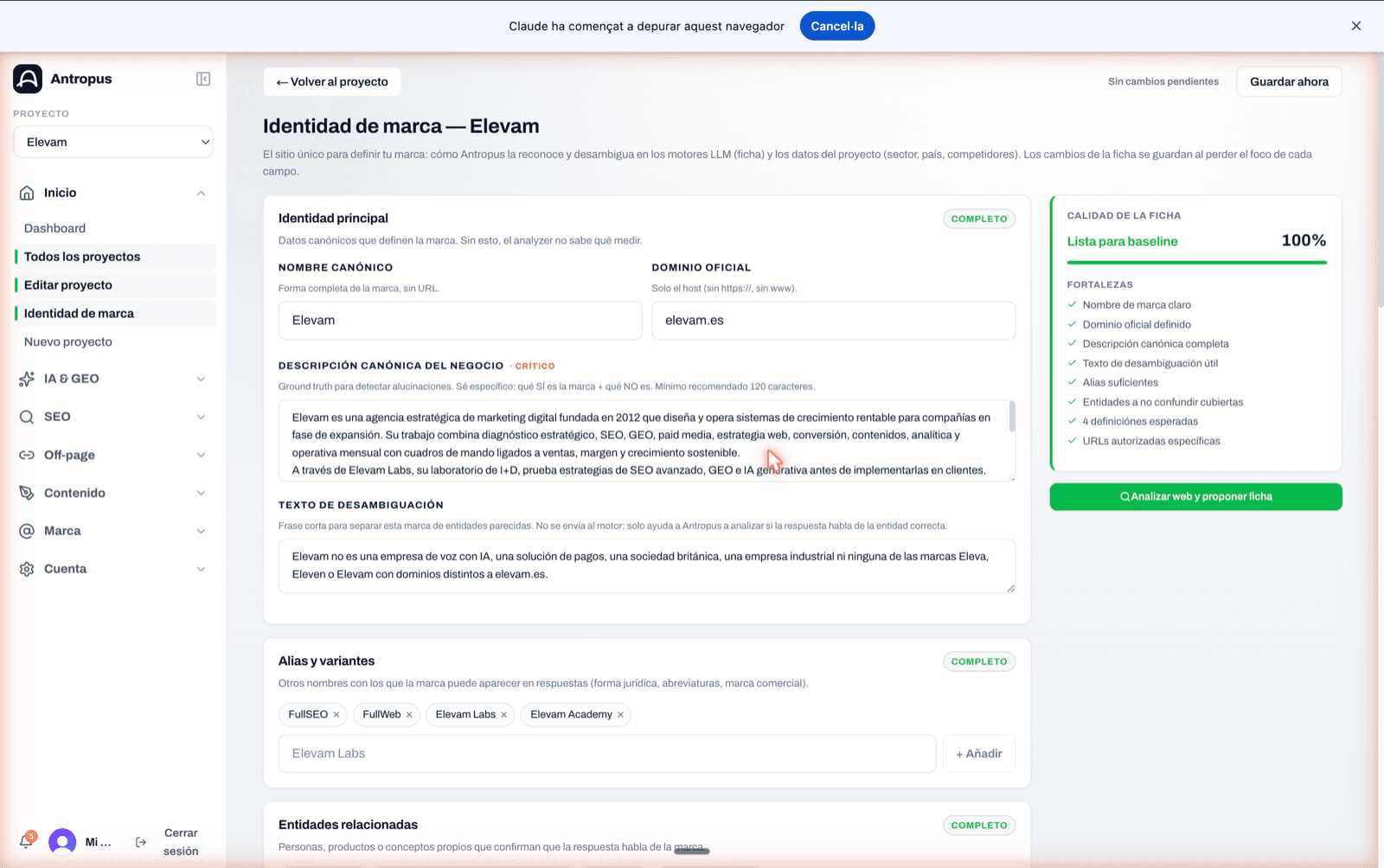
Editor de Identidad de marca (Entity Profile). Panel lateral con calidad 100 %, estado "Lista para baseline" y lista de fortalezas detectadas.
7.2 Paso 2 — Cómo medir: motores, origen de prompts y profundidad
Aquí decides exactamente con qué pones a prueba la visibilidad de tu marca. Tres bloques:
Motores. Antropus permite seleccionar manualmente, uno a uno, sobre qué fuentes corre el baseline. Las disponibles hoy son seis: Claude, ChatGPT, Gemini, Perplexity, Google IA (modo generativo) y Google AI Overview (el bloque real de la SERP). No hay presets: tú eliges. Cuanto más motores actives, más fiable la lectura, pero también más coste.
Origen de los prompts. Tres opciones: generación metodológica automática (Antropus crea los prompts respetando A–F), usar un set guardado de la biblioteca del proyecto, o añadir manualmente (pegando o escribiendo). Para una primera auditoría usamos la automática; para auditorías recurrentes, el set guardado, que garantiza que comparamos manzanas con manzanas trimestre a trimestre.
Profundidad del baseline. Un slider de 5 a 25 prompts. La pantalla indica si la elección es "Medición mínima" (≤ 5 prompts, prueba rápida con cobertura limitada) o si entra en la zona metodológicamente sólida (≥ 12 prompts). Los chips A–F debajo recuerdan qué categorías cubrirá el set.
La elección de "5 prompts × 4 motores = 20 tests" no es la habitual de un cliente real. Para un cliente serio recomendamos al menos 15 prompts y 3 motores, lo que da entre 45 y 60 tests. Para auditoría de cabecera, 30 prompts × 4 motores ≈ 120 tests.
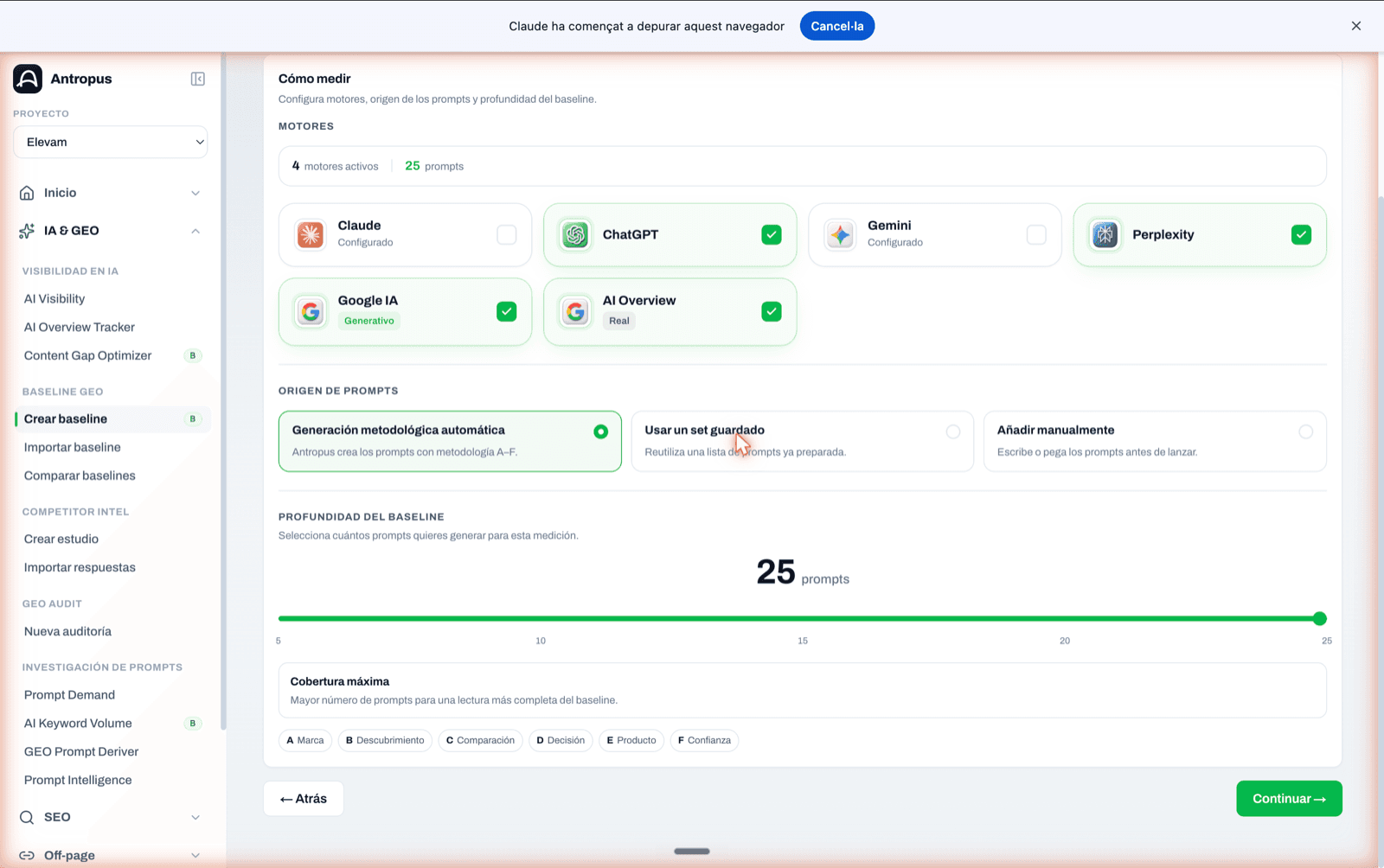
Paso 2 "Cómo medir". Selección manual de los motores disponibles, origen de prompts y slider de profundidad del baseline.
7.3 Paso 3 — Revisar y configurar el mapa de intención
Antes de lanzar nada, Antropus te enseña un resumen: motores activos, número de prompts, número de tests resultantes, coste estimado en créditos, marca, URL, sector, país, competidores y origen de los prompts. Es la última oportunidad de cambiar algo sin haber gastado.
En este mismo paso 3 está, plegado, el editor del mapa de intención → URL canónica. Si el proyecto ya tenía mapa configurado, ves un badge "Mapa completo" y el número de clusters guardados. Si no, puedes configurarlo aquí mismo sin salir del flujo: cada cluster con su URL canónica, sus URLs aceptables y sus URLs problemáticas, con el motivo de por qué son problemáticas (home absorbe específica, investigación absorbe comercial, activo incorrecto, etc.).
Este paso es opcional, pero muy recomendado: sin mapa, las métricas básicas (SoR, BCR, Top 3) siguen funcionando, pero pierdes el 80 % del análisis estructural —drift, canibalización, recomendaciones de arquitectura—.
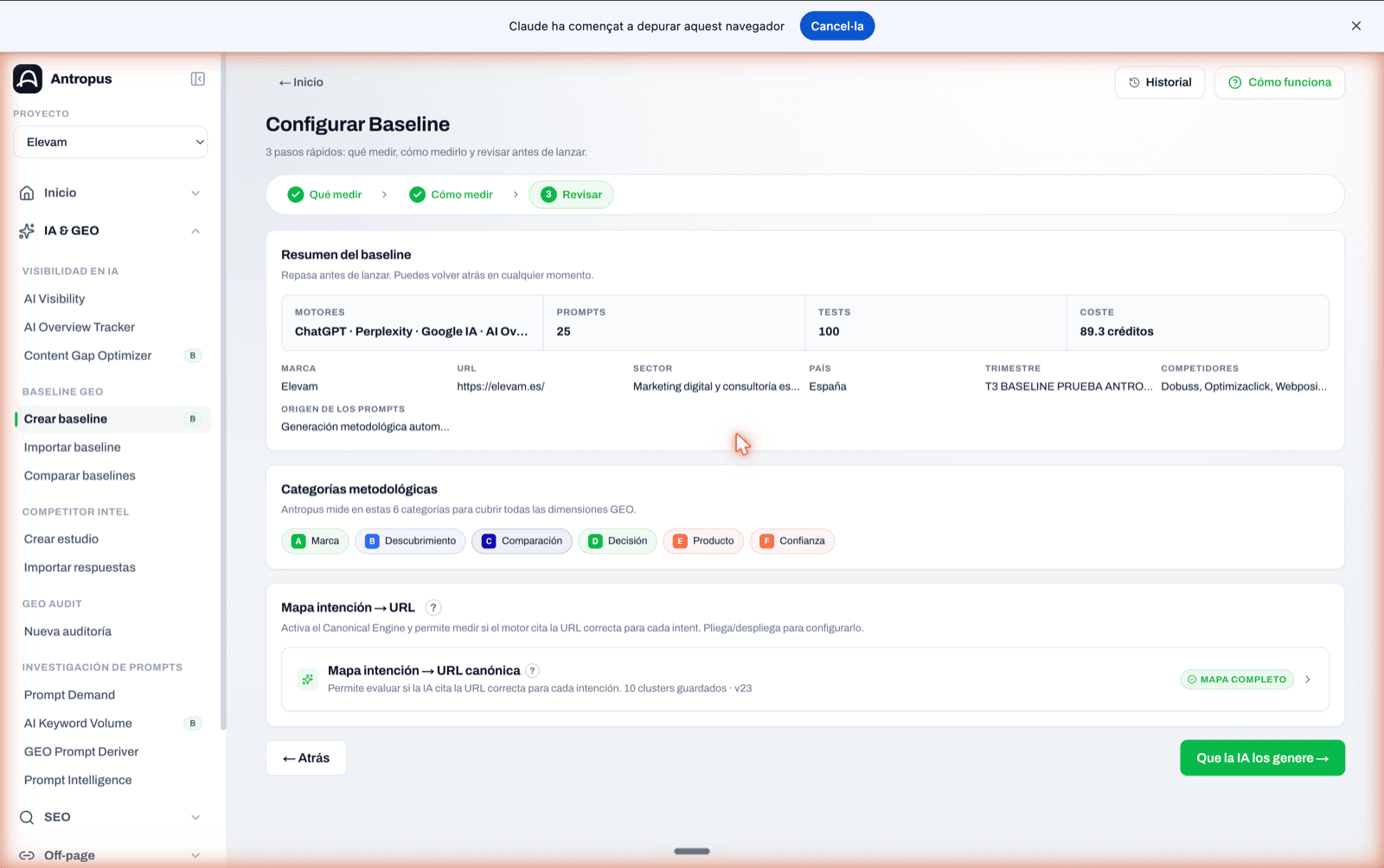
Paso 3 "Revisar": resumen del baseline antes de lanzar, chips de las seis categorías metodológicas y editor del mapa de intención plegable.
7.4 Generación y revisión del set de prompts
Al pulsar "Que la IA los genere", Antropus arranca un proceso visible: analiza el contexto del negocio, construye la distribución metodológica, genera por turno cada una de las seis categorías (B → D → C → A → E → F), valida la distribución global (B+C+D ≥ 51 %, A ≤ 30 %) y detecta sesgos a marca y duplicados semánticos. Lo ves en una lista con un check verde por cada paso completado.
Inmediatamente después llegas a la pantalla "Revisar prompts". Ahí, antes de lanzar, ves:
- El panel de distribución metodológica, con un score global y avisos cuando algo no cuadra (por ejemplo, "B+C+D representan 50 % del set. Mínimo metodológico 51 %").
- La lista de prompts agrupada por categoría A–F, con su texto, su categoría y la columna "URL canónica" por prompt.
- Un dato importante: si tienes mapa de intención configurado, Antropus autocompleta automáticamente la URL canónica de cada prompt según su categoría. En la pantalla aparece un aviso ("X URLs canónicas autocompletadas desde el mapa de intención") y los prompts entran ya con su URL alineada. Si quieres una URL distinta para un prompt concreto, la sobrescribes ahí.
- Botones para añadir prompts a mano, pegar varios a la vez, copiar la lista o volver al origen.
Aunque Antropus los genere con metodología, siempre revisamos antes de lanzar. Reescribimos los prompts que no tienen el ángulo natural del sector, recategorizamos los mal clasificados y desactivamos los que no aplican (sin borrarlos, por si se reactivan el trimestre que viene).
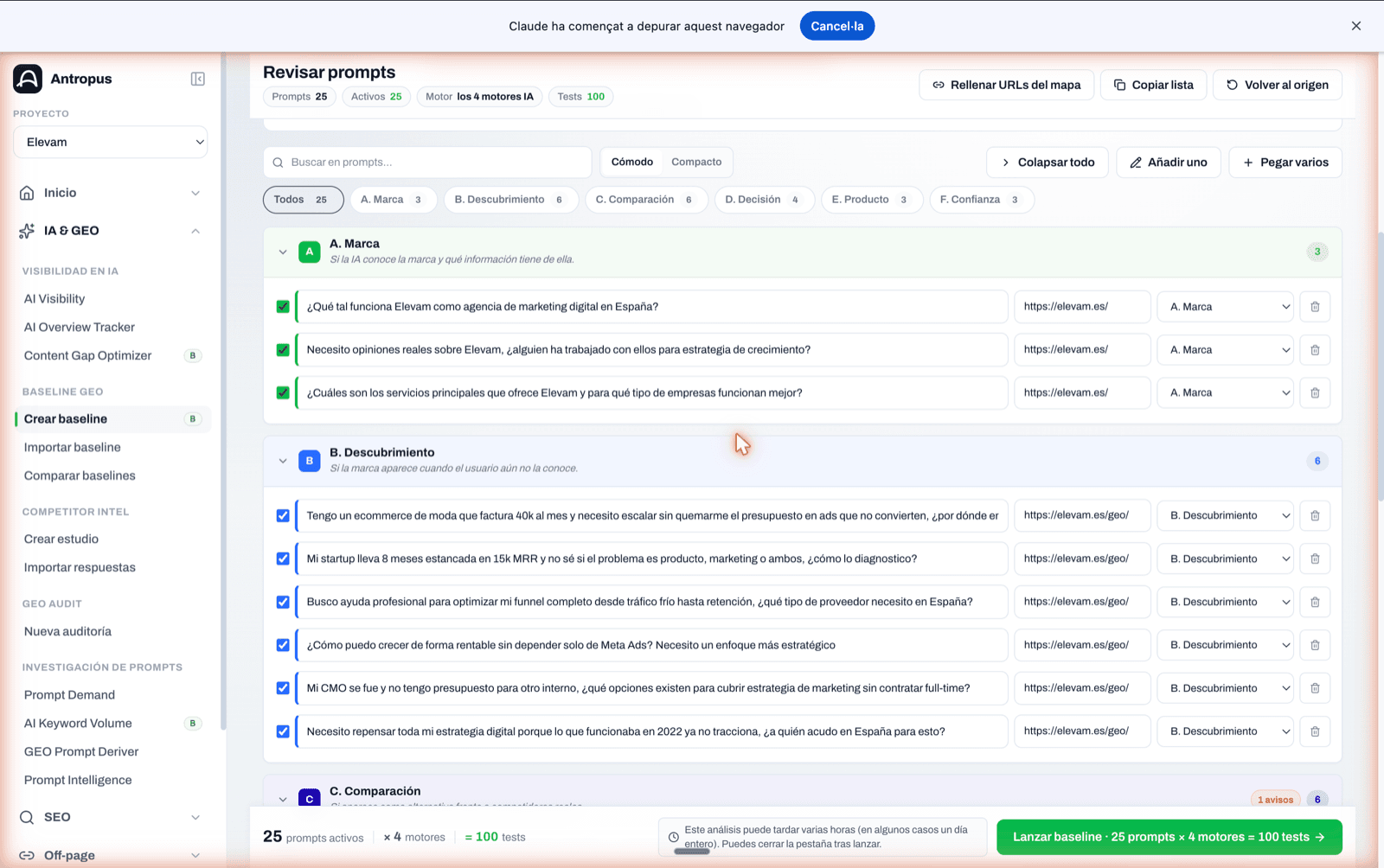
Pantalla de revisión de prompts: cada categoría A–F como sección colapsable, con su texto, URL canónica autocompletada y selector de categoría.
7.5 Lanzar y monitorizar
Pulsas "Lanzar baseline" y el trabajo se encola en el backend, que corre asíncrono por lotes y va guardando el progreso. En la práctica, esto significa tres cosas que importan más de lo que parece:
- Puedes cerrar la pestaña. El baseline sigue corriendo y, al volver, ves el progreso real.
- Si un motor falla técnicamente (timeout, cuota), ese test se marca como fallido y el lote continúa. El trabajo no se cae entero por un proveedor que tuvo un mal día.
- Puedes cancelar a mitad si ves que algo va mal; los tests ya completados se conservan.
La pantalla "Baseline en curso" tiene un núcleo de progreso ("AI Execution Core") con un anillo SVG, el porcentaje grande en el centro y nodos por motor alrededor (verde = completado, azul = en curso, gris = pendiente). Una barra lineal arriba muestra "X/N tests" y "X % completado". Más abajo: cards por motor con su estado individual, prompt actual destacado, cola de prompts pendientes y una línea de fases.
Un baseline pequeño (5 prompts × 4 motores = 20 tests) tarda entre 3 y 8 minutos. Uno estándar (30 prompts × 4 motores = 120 tests) puede irse a 20–35 minutos según rendimiento de proveedores.
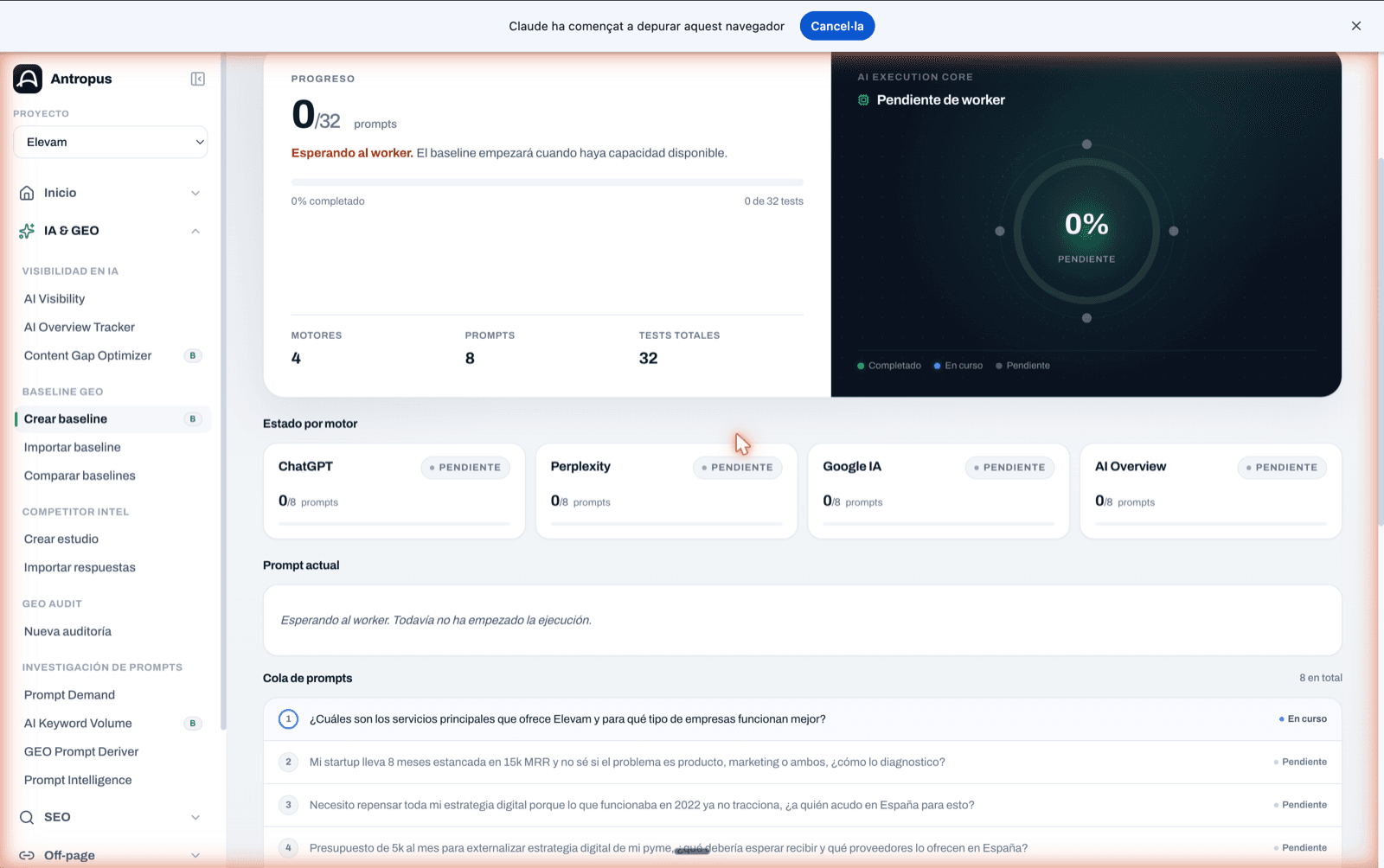
AI Execution Core: anillo SVG con porcentaje en el centro y nodos por motor alrededor (verde = completado, azul = en curso). Cards por motor + prompt actual.
8. Cómo leer e interpretar los resultados
Aquí empieza el trabajo de consultor de verdad. Antropus te da los números y el diagnóstico estructurado; tú los conviertes en recomendaciones. Estas son las cuatro lecturas que hacemos siempre.
8.1 Lectura 1 — Los cuatro indicadores de cabecera
Las combinaciones de SoR, BCR, R y Top 3 te dan la foto macro de un solo golpe:
- SoR alto + BCR bajo: la IA te recomienda pero no te enlaza. Problema de citación, no de visibilidad.
- BCR alto + R bajo: te enlazan, pero a la URL equivocada. Problema de canónica, no de citación.
- R alto + Top 3 bajo: la URL correcta aparece, pero no arriba. Problema de relevancia o autoridad para esa intención.
- Todos bajos: problema de fondo. Probablemente faltan señales de entidad o el cliente no tiene contenido suficiente.
Ese es el primer corte del informe.
8.2 Lectura 2 — La taxonomía de fallos
Antropus clasifica los fallos en 15 tipos con severidad escalada por valor comercial. Agrupados:
- Alucinaciones: confusión de entidad; ambigüedad de siglas; atribución errónea de autoría; desvío de tema; afirmación favorable sin fuente; URL que no responde a la intención.
- Canónica: drift canónico (URL propia distinta a la esperada); dispersión de fuentes; debilidad de fuente propia (te mencionan, pero sin citar nada tuyo).
- Fuentes: dependencia de terceros (tu visibilidad cuelga solo de fuentes ajenas); dominancia de competidores (citan a la competencia y a ti no, o no en el top 3).
- Activación: fallo de activación de categoría (pregunta sin marca y sin mención en B/D/E/F); fallo de shortlist comparativo (categoría C sin top 3).
Y cada fallo viene con cuatro cosas: un título humano ("Drift canónico", "Confusión de entidad"…), una descripción de qué pasa, su impacto en lenguaje de negocio ("pérdida de control de la URL que captura demanda comercial") y un tipo de solución sugerida que enlaza directamente con la herramienta de Antropus que lo resuelve.
8.3 Lectura 3 — Severidad escalada por valor comercial
Un drift canónico en categoría A (marca) es severidad alta. El mismo drift en categoría D (decisión comercial) escala a crítica, porque cuesta dinero de verdad. Las categorías de alto valor son D (decisión), C (comparación) y B (descubrimiento): cualquier fallo en ellas sube un escalón de severidad respecto al mismo fallo en A, E o F.
Esto te ahorra trabajo: cuando entregas el informe, las acciones priorizadas no son "las que tienen más fallos", sino las que más impacto comercial tienen.
8.4 Lectura 4 — Acciones recomendadas con criterio de éxito
Cada fallo genera una acción con prioridad (1–3), una herramienta destino (un enlace directo a la función de Antropus que lo resuelve: editor de entidad, copywriter, arquitectura de contenido…) y un criterio de éxito medible. Por ejemplo: "Citation Rate ≥ 50 % en categoría D en el próximo baseline."
Eso es lo que entregas como hoja de ruta. No "tu visibilidad es media" (inútil), sino "estos siete problemas, en este orden, con esta herramienta, y validamos el resultado con esta métrica en tres meses".
Pestaña "Inteligencia" con fallos detectados clasificados por severidad, acciones priorizadas con su métrica objetivo y criterios de éxito.
9. El aviso metodológico y la trazabilidad estadística
Una auditoría seria reconoce sus límites por escrito. En Antropus, todo PDF exportado lleva un aviso metodológico automático. Y por debajo, el motor aplica una serie de reglas de honestidad estadística que la mayoría de herramientas se salta. Las dos cosas, juntas, son lo que de verdad diferencia un informe que aguanta una revisión externa de uno que se cae al primer pinchazo.
9.1 Lo que tu auditoría GEO debe declarar (siempre)
- Los modelos de IA no son deterministas. La misma pregunta puede dar respuestas distintas en ejecuciones seguidas. Por eso un baseline es una muestra, no una verdad absoluta. Para detectar cambios reales, comparamos varios tests por motor y miramos la varianza.
- El grounding web es imperfecto. Las búsquedas web de los proveedores pueden devolver fuentes incorrectas o no devolver ninguna pese a haberlas consultado. Antropus lo detecta y lo señala (por ejemplo, las redirecciones opacas de Gemini, que ocultan el dominio real bajo URLs del tipo vertexaisearch.cloud.google.com/grounding-api-redirect/…).
- Las marcas parecidas se confunden. Sin una ficha de entidad bien hecha, los homónimos producen falsos positivos. Antropus puntúa la calidad de la ficha en cuatro estados y desaconseja medir si está en los dos peores.
- Las muestras pequeñas tienen mucha varianza. Antropus desaconseja sacar conclusiones de baselines con menos de 15 prompts. Una métrica sobre 5 evaluables no tiene poder estadístico.
- No prometemos "posición garantizada en ChatGPT". El modelo cambia, el modo cambia, la app cambia. Lo que sí prometemos es metodología repetible y diagnóstico claro. Quien te prometa lo primero te está vendiendo humo.
- El Triggering Rate de AI Overview varía. No todas las búsquedas activan el bloque generativo. Antropus lo mide y separa "Google no mostró el bloque" de "tu marca no apareció", dos cosas que la mayoría de herramientas mezcla.
Declarar estos límites no te resta credibilidad. Te la da. El cliente que entiende que una herramienta reconoce sus márgenes de error es el mismo que confía en ti el trimestre siguiente.
9.2 Las siete reglas de honestidad estadística
- Si no se puede medir, no se inventa. Cuando el denominador es 0, la métrica es "no medible", no 0. En el dashboard sale "—"; en el Excel, vacío. Un 0 silencioso engaña al cliente.
- El "no medido" se filtra del SoR. "No lo he medido" no es "es la peor opción". Distinguirlo es la diferencia entre un SoR honesto y uno corrompido por baselines viejos.
- Los tests con confusión de entidad salen del denominador de visibilidad. Si Gemini te confundió con un homónimo, ese test no infla tu SoM: entra en la tasa de validez metodológica.
- La heterogeneidad se declara. Si la diferencia entre el mejor y el peor motor supera los 40 puntos porcentuales, el global se marca como heterogéneo y el dashboard avisa de que no saques conclusiones de la media, porque un motor la está distorsionando.
- En la SERP generativa, "se disparó" y "no se disparó" van separados. Si Google no mostró el bloque, ese test no entra en visibilidad: entra en Triggering Rate. Métricas distintas, interpretaciones distintas.
- Avisos automáticos por tamaño de muestra. Menos de 12 prompts: aviso. Menos de 15: recomienda ampliar. Menos de 5 evaluables: el motor de inteligencia se niega a diagnosticar.
- La fiabilidad de fuentes pondera por opacidad. Las URLs opacas (las redirecciones de Gemini) penalizan el score; las auditables lo suben. La cuota de voz ponderada usa este score, de modo que una mención en Perplexity con fuente oficial pesa más que una en Gemini con redirección.
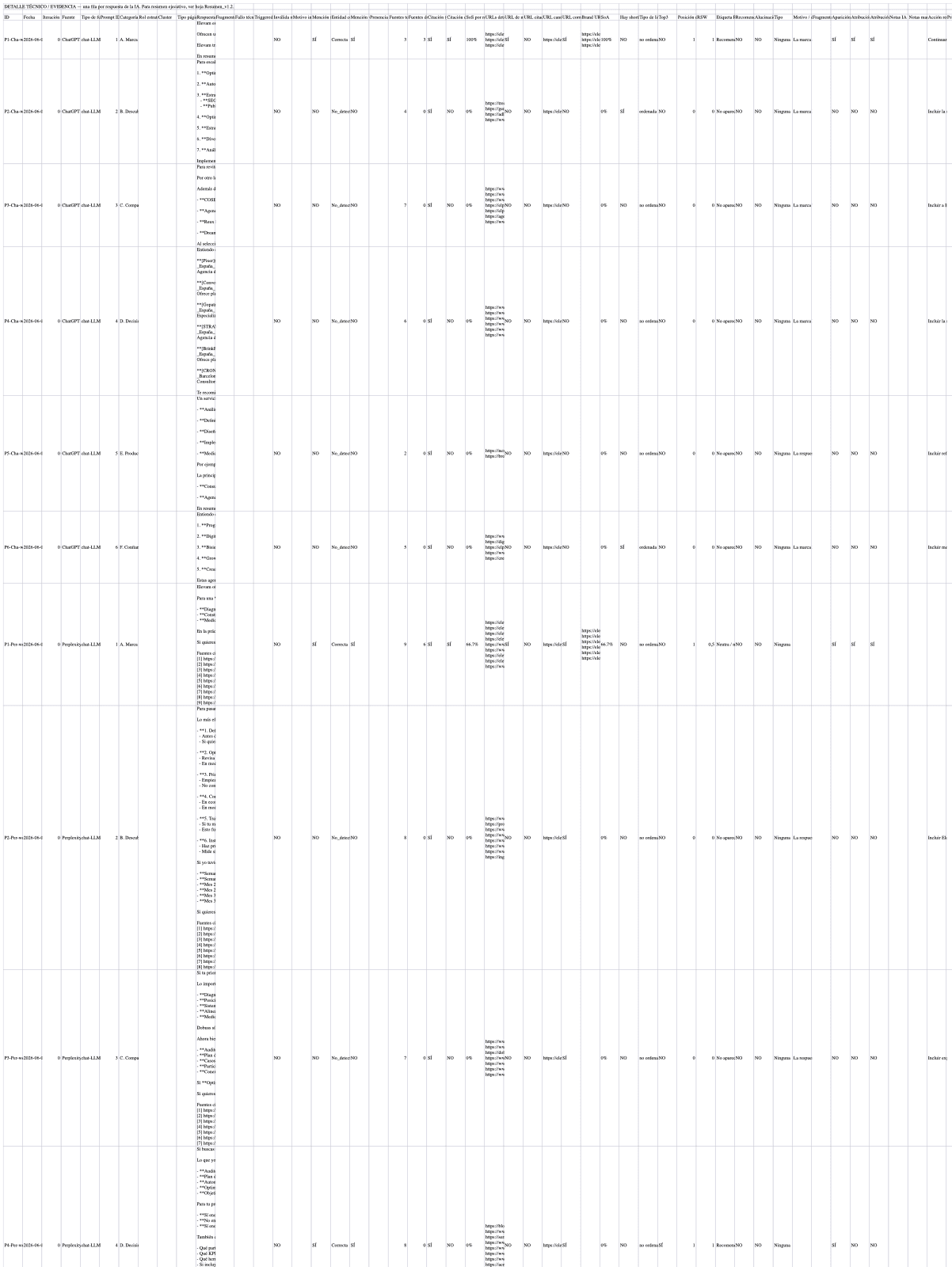
Detalle del Excel descargable. Cuando una métrica no se puede calcular, la celda lleva "—" en lugar de "0"; tabla limpia, sin colorinchismo.
10. ¿Cuánto se tarda en hacer una auditoría GEO seria?
Para que tengas una referencia real, este es el desglose de una auditoría completa tal y como la entregamos en Elevam:
| Fase | Tiempo |
|---|---|
| Setup del proyecto + ficha de entidad | 30–60 min |
| Mapa de intención | 45–90 min (según el tamaño del sitio) |
| Generación de prompts | 5 min (auto) + 15–30 min de revisión humana |
| Ejecución del baseline (30 prompts × 4 motores ≈ 120 tests) | 20–35 min automático |
| Análisis y redacción del informe | 2–4 horas |
| PDF/Excel entregable (con aviso metodológico incluido) | 30 min automático |
En total, aproximadamente una jornada de trabajo de consultor. Si el cliente quiere máxima profundidad (60 prompts × 6 motores, en torno a 360 tests con todos los SERP-generativos activos), se va a jornada y media. Pero el resultado justifica sin problema una factura de cuatro cifras —a menudo de varios miles de euros—, sobre todo si lo empaquetas bien (auditoría puntual, o auditoría + remediación + segundo baseline para validar resultados).
11. Errores que vemos una y otra vez en auditorías GEO previas
Cuando un cliente nos enseña la auditoría que le hicieron antes, casi siempre encontramos los mismos fallos:
- Midieron solo en ChatGPT. Como si fuera el único motor. Claude, Gemini, Perplexity y el bloque AI Overview de Google también tienen audiencia, y los resultados pueden ser muy distintos. Una auditoría seria mide en al menos tres motores.
- No separan memoria de web. Los resultados cambian radicalmente. Un baseline serio mide los dos modos donde el motor lo permite y, además, incluye el SERP-generativo de Google para ver qué cuenta Google sin que el usuario abandone el buscador.
- El SoM sale al 80 % porque el set era 100 % de marca. Ya lo hemos dicho, pero merece repetirse.
- No hay ficha de entidad. El analizador no distingue la marca de sus homónimos. Falsos positivos sistémicos.
- No hay mapa de intención. Solo miran "¿salió alguna URL del dominio?". No detectan ni canibalización ni drift.
- Métricas sin denominador. "Citation Rate 35 %." ¿Sobre qué? ¿Tests totales? ¿Evaluables? ¿Visibles? Sin saberlo, el número es ruido.
- Promesas imposibles. "Vas a salir en el top 3 de ChatGPT en 90 días." Eso no se puede prometer, porque ni el modelo, ni el modo, ni la app son estables.
Cuando llega un cliente con un informe así, la conversación es fácil: "esto no es una auditoría GEO, es el material de venta del que te lo hizo. Te enseño cómo se hace bien".
12. Preguntas frecuentes sobre la auditoría GEO
¿Qué es exactamente una auditoría GEO?
Es la medición sistemática de cómo aparece tu marca en las respuestas de los motores de IA generativa (ChatGPT, Claude, Gemini, Perplexity) y en el bloque AI Overview de Google: si te mencionan, en qué posición, si citan tu web y si te confunden con otra empresa.
¿En qué se diferencia una auditoría GEO de una auditoría SEO?
El SEO mide tu posición en los resultados de búsqueda de Google. La auditoría de visibilidad en IA mide tu presencia dentro de respuestas generadas, que no tienen posiciones ni clics al uso. Son disciplinas complementarias, con herramientas y métricas propias.
¿Cómo se evita que las métricas salgan infladas?
Repartiendo las preguntas en seis categorías obligatorias —con entre un cuarto y un tercio de preguntas genéricas, donde la marca solo aparece si de verdad se la recomienda—, sin contar como acierto las confusiones de marca y mostrando un "—" cuando no hay muestra suficiente para una cifra fiable.
¿Qué herramienta usáis para hacer la auditoría GEO?
Usamos Antropus, la plataforma de SEO y GEO desarrollada por Elevam Labs. Permite medir cuatro LLMs (Claude, ChatGPT, Gemini, Perplexity) más Google IA y AI Overview, con resolución de entidad, mapa de intención y un motor que convierte las métricas en acciones priorizadas.
¿Cada cuánto conviene repetir una auditoría de visibilidad en IA?
Lo recomendable es trimestral, usando el mismo set de prompts para que la comparativa sea válida. Los modelos cambian con frecuencia, y solo midiendo con regularidad detectas a tiempo si tu visibilidad sube o baja.
¿Se puede garantizar aparecer en ChatGPT o en Google AI Overview?
No, y desconfía de quien lo prometa. Lo que sí se puede es medir con rigor, diagnosticar dónde fallas y trabajar las señales (entidad, contenido, citaciones, arquitectura) que aumentan tus probabilidades de aparecer.
13. Conclusión
Una auditoría GEO seria no es lanzar 30 prompts a ChatGPT y resumir el resultado en un PDF. Es un protocolo de medición con metodología cerrada, métricas que sabes calcular, una taxonomía de fallos clara y unos márgenes de error declarados.
Lo que conviene llevarse:
- La auditoría de visibilidad en IA mide algo distinto del SEO clásico. Necesita herramientas y metodología propias.
- Los prompts deben repartirse en seis categorías (A–F) con distinta política de marca. Un set sesgado hacia A produce métricas infladas e inútiles.
- El SoR (ponderado por fuerza de recomendación) es la métrica titular de un dashboard GEO serio. El SoM (binario) es secundario.
- El mapa de intención → URL canónica activa el análisis estructural: drift, canibalización, URLs problemáticas. Sin él, pierdes el 80 % del valor.
- Las confusiones de entidad no inflan el SoM: salen del denominador. Así se evitan los falsos positivos.
- Si no se puede medir, no se inventa. La heterogeneidad se declara. Las muestras pequeñas se avisan. Esto se le cuenta al cliente; no se esconde.
En Elevam usamos Antropus para todas nuestras auditorías GEO. Es lo que nos permite respetar todo lo anterior sin trabajo manual masivo: backend asíncrono resiliente, un motor de inteligencia que convierte métricas en acciones priorizadas y exportable a PDF con aviso metodológico incluido.
Sobre Antropus
Antropus.io es la plataforma de SEO y GEO desarrollada por Elevam Labs, el laboratorio de producto de la agencia Elevam, dirigida por Asier López Ruiz. Combina datos reales de proveedores profesionales del sector con análisis de IA propio para auditar la visibilidad de las marcas tanto en buscadores como en motores generativos, en una sola suite y con un enfoque centrado en la honestidad de los datos.


