Com muntar una auditoria de visibilitat en IA que aguanti una auditoria: amb mètriques que saps calcular, una taxonomia d'errors clara i accions prioritzades per impacte comercial. De la teoria al pas a pas real amb la plataforma que fem servir a Elevam per a això: Antropus.
Vols saltar-te la teoria i que ho fem per tu? Sol·licita una auditoria GEO per a la teva marca i t'ensenyem exactament on apareixes (i on no) a les respostes d'IA.
1. Què és una auditoria GEO (i per què no és SEO)
Comencem per la definició, perquè mig sector la fa servir malament.
Una auditoria GEO (de Generative Engine Optimization) és el procés de mesurar, avaluar i diagnosticar la presència d'una marca als motors d'intel·ligència artificial generativa. En concret, en sis superfícies:
- ChatGPT (OpenAI)
- Claude (Anthropic)
- Gemini (Google)
- Perplexity (Sonar)
- El mode generatiu de Google (la resposta conversacional dins del mateix Google)
- Google AI Overview (el bloc generatiu que apareix per sobre dels resultats orgànics)
El SEO clàssic respon a "quina posició ocupo a Google per a aquesta keyword?". Una auditoria de visibilitat en IA respon a una altra pregunta, diferent i avui més urgent:
Quan un usuari pregunta a una IA pel meu sector, apareix la meva marca? En quina posició? Citen el meu web o el d'un competidor? La IA em coneix de debò o em confon amb una altra empresa?
La diferència no és de matís, és de naturalesa. Google Search Console et dóna impressions, clics, CTR i posició mitjana. Els models generatius no et donen res d'això. Quan algú pregunta a ChatGPT, rep un text redactat, de vegades amb fonts i de vegades sense. Ningú t'avisa que la teva marca va sortir, que et van confondre amb una altra o que van recomanar el teu competidor. La resposta és, literalment, una caixa negra.
Per obrir aquesta caixa cal un protocol de mesurament sistemàtic i repetible. Això, i no un grapat de captures de pantalla, és una auditoria GEO.
“El SEO ens diu com ens troba Google. El GEO ens diu com ens explica una IA. I cada cop més decisions de compra comencen a la segona conversa, no a la primera cerca.
”
1.1 SEO clàssic, GEO i mesurament d'IA: tres coses diferents
| Disciplina | Què mesura / Font de la dada |
|---|---|
| SEO clàssic | Posició orgànica a Google, impressions, clics, backlinks · Search Console i proveïdors de dades de SEO |
| GEO | Com apareix la marca als motors d'IA: freqüència, posició, citació, confusió d'entitat · Tests propis contra les IAs + un analitzador |
| Mesurament d'IA | La capa que uneix els dos mons: separa el que ve del cercador del que ve de l'assistent · Antropus ho orquestra i ho compara |
Avui un client seriós necessita les tres. Però aquesta guia va de la del mig, que és la que gairebé ningú sap fer bé.
2. Per què la teva marca necessita una auditoria de visibilitat en IA ara
No és una moda. És un canvi de canal, i va de pressa.
Quan algú pregunta "millor agència de GEO a Espanya" a ChatGPT i es queda satisfet amb la resposta, aquest usuari no arriba mai a Google. El trànsit que captes al cercador per a aquesta intenció és, cada cop més, només la fracció que la IA no va resoldre. És a dir: el que veus a Search Console és la punta de l'iceberg, i l'iceberg està creixent per sota de l'aigua, on la teva analítica clàssica no mira.
La mida d'aquest "sota l'aigua" ja no és anecdòtica. Segons OpenAI (febrer de 2026), ChatGPT supera els 900 milions d'usuaris actius setmanals i s'acosta als mil milions. Suma-hi els centenars de milions de Gemini, la base de Claude i el creixement de Perplexity com a cercador alternatiu, i tens audiències senceres que la teva estratègia de SEO clàssic, senzillament, no mesura.
I després hi ha Google jugant als dos taulers alhora: en moltíssimes cerques informacionals i bastantes comercials, el bloc d'AI Overview apareix per sobre dels resultats orgànics. Si la teva marca no entra en aquesta resposta sintetitzada, has perdut el clic abans que l'usuari arribi tan sols a la llista d'enllaços blaus.
Així que la pregunta no és si necessitaràs mesurar la teva visibilitat en IA. La pregunta és quan t'assabentes que ja l'estaves perdent i ningú t'avisava.
2.1 Quins problemes concrets resol una auditoria GEO ben feta
Una auditoria seriosa et permet, a la pràctica:
- Saber si la teva marca apareix (o no) en respostes a preguntes reals del teu sector.
- Detectar si la IA et coneix bé o et confon amb un homònim. Ens ha passat amb la nostra pròpia marca: en certes proves, Elevam apareixia confosa amb ElevenLabs.
- Veure si la IA recomana la teva competència al teu lloc, i en quin tipus de preguntes exactament.
- Identificar quina URL del teu lloc cita la IA i si és la correcta per a aquesta intenció.
- Descobrir canibalització: el teu blog ocupant el lloc que hauria d'ocupar la teva landing de serveis.
- Quantificar quantes de les teves aparicions són recomanacions fortes i quantes són mencions de farciment sense valor comercial.
- Tenir un baseline quantitatiu i comparable trimestre a trimestre per saber si les teves accions d'optimització funcionen o no.
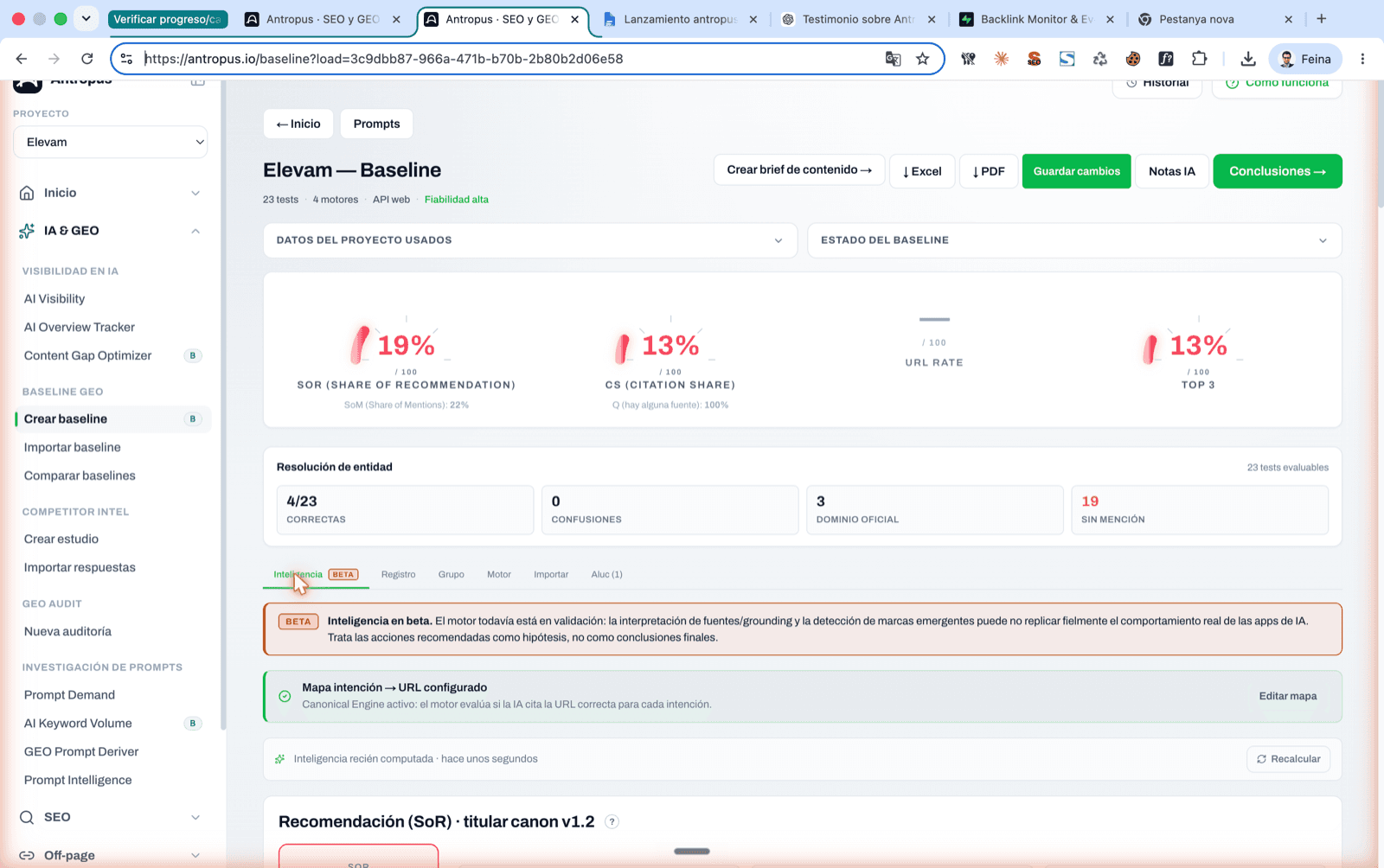
Pantalla principal d'un baseline finalitzat a Antropus, amb els 4 indicadors titulars (SoR, CS, URL Rate, Top 3) i la resolució d'entitat.
3. L'error que comet la majoria d'auditories GEO
Abans d'explicar com ho fem a Elevam, cal desmuntar el que es ven per aquí. La majoria de les "auditories GEO" que arriben a les nostres mans —normalment quan un client ens ensenya la que li van fer abans— falla en almenys un d'aquests tres punts. I tots tres tenen el mateix efecte: un informe que sembla bo i no serveix per a res.
3.1 Prompts esbiaixats cap a la marca
És l'error més comú i el més car. El consultor llança 30 preguntes a ChatGPT, però totes són d'aquest estil:
- "Què opines de [marca]?"
- "Opinions sobre [marca]"
- "[Marca] és de fiar?"
- "Compara [marca] amb [competidor]"
La IA està obligada a parlar de la marca a cada resposta, perquè el prompt l'anomena. El resultat: un Share of Mentions del 90%. El consultor l'hi ensenya al client com un triomf. No està mesurant res útil.
El que el client necessita saber és si la IA el recomana quan l'usuari encara no el coneix. I això només es mesura amb preguntes a cegues (blind), del tipus:
- "Quina és la millor agència de SEO a Madrid?"
- "Recomana'm plataformes per gestionar GEO"
- "Quines eines fan servir les agències per mesurar la seva visibilitat en IA?"
Si la teva marca no surt aquí, no estàs captant demanda nova en IA. Tan simple com això. I si la teva auditoria no mesura això, la teva auditoria no és una auditoria: és el fullet comercial del consultor per justificar la factura següent.
3.2 Mètriques binàries disfressades de mètriques ponderades
El segon error: fer servir el Share of Mentions (SoM) com a mètrica estrella. El SoM és binari: compta si la marca va aparèixer o no, i res més. No distingeix la força amb què et recomanen.
Compara aquestes dues respostes:
- "Et recomano [marca]; és la millor opció del mercat, i t'explico per què…"
- "Hi ha moltes opcions; algunes són X, Y, Z, i també hi ha [marca]."
Totes dues sumen exactament el mateix al SoM. Però la primera val deu vegades la segona. Sense una mètrica que ponderi la força de la recomanació, la teva auditoria llença a les escombraries la meitat de la informació que importa.
La mètrica que sí que pondera és el SoR (Share of Recommendation), i és la mètrica titular del tauler d'Antropus. El problema és que el mercat encara no la fa servir, així que gairebé ningú la reporta. Hi tornem en detall més avall.
3.3 Denominadors trampaires
El tercer és estadístic, sembla menor i arruïna informes sencers. Imagina que llances 30 prompts a Gemini amb web activa i 8 fallen tècnicament (timeout, quota esgotada). No pots calcular el teu Citation Rate com 2 / 30 = 6,6 %. Aquests 8 no són "respostes en què no et van citar"; són respostes que no van arribar a existir. El càlcul honest és 2 / 22 = 9 %.
La mateixa dada, dos denominadors
Un detall de denominador, una diferència enorme a l'informe: comptar els 8 tests fallits com a "no em van citar" subestima la teva presència i lliura un diagnòstic falsament alarmant.
4. Les sis categories obligatòries de prompts (A–F): el cor de la metodologia
Una auditoria GEO seriosa no deixa que escriguis les preguntes al teu gust. Força una distribució metodològica que neutralitza el biaix de marca. A Antropus les anomenem categories A–F, i són obligatòries en tot baseline.
4.1 El catàleg
| Cat. | Nom | Què mesura | Política de marca | % per defecte |
|---|---|---|---|---|
| A | Marca i reputació | Si la IA coneix la teva marca i què en sap | Sempre amb marca | 10–15 % |
| B | Descobriment genèric | Si apareixes quan l'usuari NO et coneix | Mai amb marca | 25–30 % |
| C | Comparació competitiva | Si apareixes com a alternativa davant de competidors | Moderada | 20–25 % |
| D | Decisió comercial | Si apareixes en el moment de comprar | Mai amb marca | 15–20 % |
| E | Producte / categoria | Si apareixes en cerques tècniques o de catàleg | Mai amb marca | 10–15 % |
| F | Objeccions i confiança | Si apareixes quan l'usuari té dubtes | Rara | 10–15 % |
4.2 Per què exactament aquesta distribució
Al darrere hi ha tres regles dures, que a Antropus no són una recomanació sinó codi que s'executa:
- La categoria A mai passa del 30 % del set. Si te'n passes, estàs mesurant reputació de marca, no visibilitat GEO.
- B + C + D sumen com a mínim el 51 %. És la majoria a cegues i comercial: on de debò es decideix si captes demanda nova.
- Les sis categories han d'estar presents si el set té sis prompts o més. Cobrir només tres o quatre esbiaixa la lectura.
I per sota hi ha un ordre de prioritat per a sets petits (menys de 12 prompts): B → D → C → A → E → F. És a dir, si només pots llançar sis preguntes, les gastes en aquest ordre; no comences per A per inèrcia narcisista.
4.3 Què passa si et saltes aquestes regles
Si llances 30 prompts on 25 són de categoria A (tots amb la teva marca a dins), el teu SoM sortirà entre el 70 % i el 95 %. L'hi ensenyes al client com un èxit. I al trimestre següent, quan torneu a "optimitzar", no haurà canviat res: perquè l'auditoria no mesurava res que es pogués moure.
Antropus es nega a calcular certes mètriques si la mostra avaluable és menor de 5, i avisa de manera explícita quan el set té menys de 12 prompts ("no cobreix tota la metodologia") o menys de 15 ("mostra mínima recomanada per treure conclusions"). Preferim un "—" honest a un número que enganya.
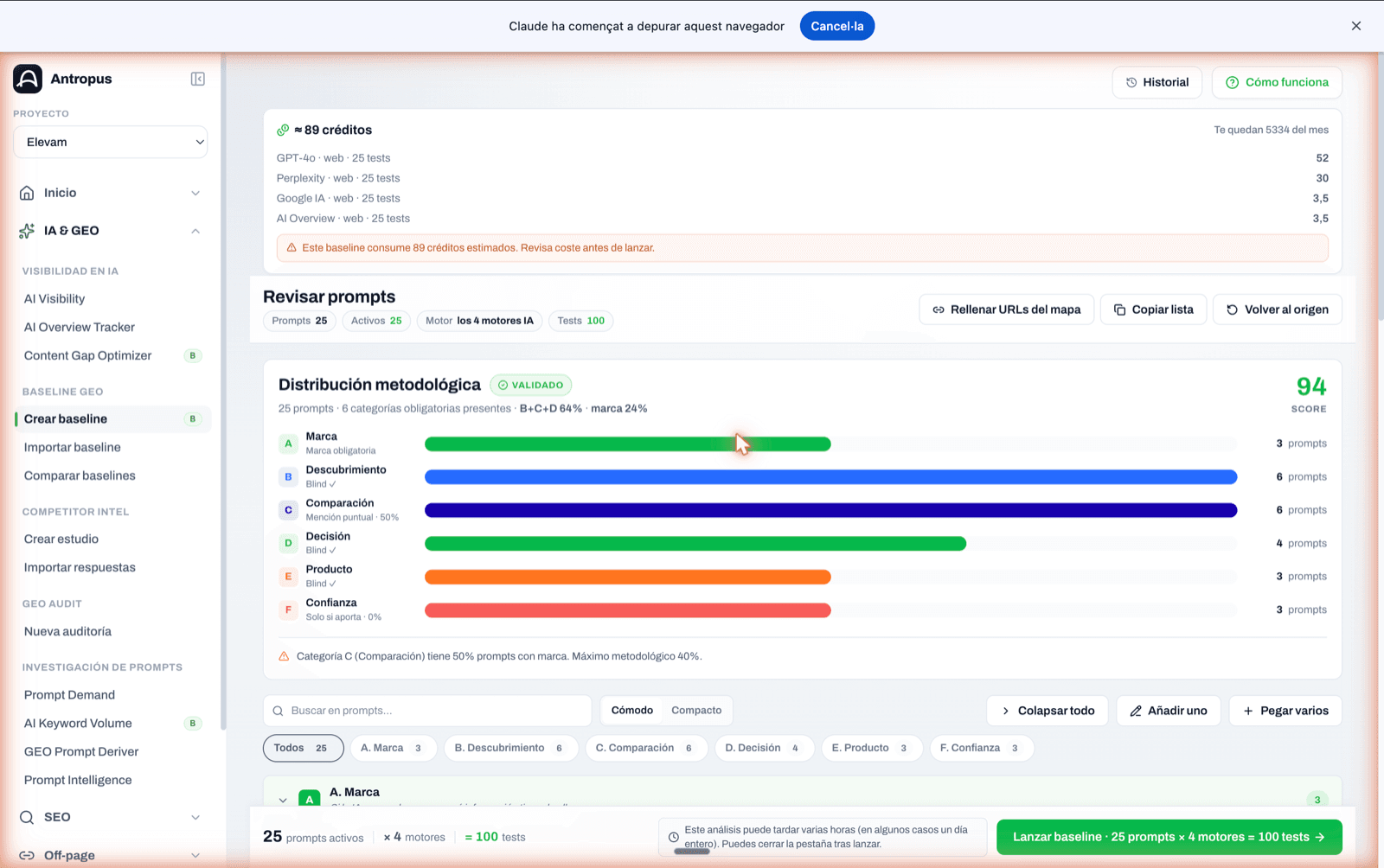
Panell de distribució metodològica d'un baseline en revisió. Puntuació 82 i avisos quan B+C+D no arriba al 51 % o quan hi ha menys de 12 prompts.
5. Les mètriques que importen: què es mesura i com es calcula
Una auditoria GEO seriosa reporta entre quatre i sis mètriques titulars, cadascuna amb el seu denominador declarat. No vint mètriques soltes sense context. Aquestes són les que pintem al tauler d'Antropus.
SoR
Share of Recommendation
La titular. Força mitjana amb què la IA et recomana.
BCR
Brand Citation Rate
% de respostes que citen una font del teu domini oficial.
R
URL Rate
% de respostes que citen la URL canònica esperada.
Top 3
Top 3 Share
% de rànquings ordenats on apareixes en posicions 1-3.
5.1 SoR — Share of Recommendation (la titular)
Què mesura: la força mitjana amb què la IA et recomana. És l'única mètrica que pondera la qualitat de l'aparició, no només la seva existència.
Com es calcula: mitjana del pes de recomanació (rsw) sobre les respostes en què aquest pes s'ha mesurat. Els valors són discrets:
| rsw | Significat |
|---|---|
| 1.0 | Apareixes com a opció principal o recomanació destacada |
| 0.75 | Ets a la shortlist, amb bona justificació |
| 0.5 | Et mencionen de manera neutra o com a alternativa secundària |
| 0.25 | Apareixes de passada, sense recomanació clara |
| 0.0 | Apareixes, però com a opció descartada o desaconsellada |
| null | No mesurat (baselines antics sense repuntuar) |
El detall que gairebé ningú respecta: el valor "no mesurat" es filtra del càlcul. No compta com a 0. Confondre "no ho he mesurat" amb "és la pitjor opció" corrompria el SoR de qualsevol baseline antic.
5.2 BCR — Brand Citation Rate (citació de marca)
Què mesura: el percentatge de respostes on apareix almenys una font del teu domini oficial.
És la mètrica principal de citació, perquè mesura si la IA atribueix el que diu a una font teva i no a un blog de tercers o a un competidor. Que et mencionin està bé; que et citin com a font està molt millor.
5.3 R — URL Rate (la URL correcta)
Què mesura: el percentatge de respostes on la IA va citar la URL canònica esperada per a aquesta intenció.
La clau és al denominador: només hi entren els tests amb URL canònica mapejada al teu Intent URL Map. Si una intenció no té clúster definit, aquest test surt del càlcul. Així no infles la mètrica amb mostres on no hi havia res a avaluar.
5.4 Top 3 Share
Què mesura: el percentatge de respostes amb rànquing ordenat en què apareixes en posicions 1, 2 o 3.
Detall metodològic important: el denominador NO és la visibilitat total, sinó només les respostes amb rànquing ordenat (llistes numerades, comparatives explícites, shortlists). Una resposta narrativa que et menciona sense estructura de llista no hi entra. Calcular un Top 3 sobre respostes sense rànquing no significa res.
5.5 Mètriques auxiliars (però gens accessòries)
| Mètrica | Què mesura |
|---|---|
| SoM (Share of Mentions) | Binària: % de respostes on apareixes. Diagnòstica, mai titular. |
| Validity Rate | % de tests metodològicament vàlids (sense confusió d'entitat ni desviació de tema) |
| Triggering Rate | Només a Google AI Overview: % de cerques on Google mostra el bloc generatiu |
| Source Reliability | Puntuació 0–100 de fiabilitat de les fonts (penalitza redireccions opaques) |
| Hallucination Rate | % de respostes amb error factual, confusió d'entitat o atribució errònia |
| Recomanació fràgil | % de recomanacions fortes (rsw ≥ 0,75) basades en una al·lucinació: visibilitat d'alt risc |
| Source Dispersion Index | URLs pròpies competint per la mateixa intenció: mesura canibalització |
| Competitor Leakage | % de respostes on apareixen URLs de competidors |
5.6 Les nou agrupacions del motor de mètriques
Aquí hi ha part de la potència real: cada mètrica no es calcula només en global, sinó agrupada per motor, mode (memòria / web), categoria A–F, intenció, tipus de demanda, rol estratègic, etapa de l'embut i URL canònica esperada.
Això et permet respondre a les preguntes que de debò fa un client: "En quin motor em va pitjor?", "Quin tipus de pregunta activa millor la meva marca?", "Quina URL del meu lloc està rendint més?", "En quina intenció concreta estic perdent quota davant de la meva competència?". I tot sense exportar a Excel ni barallar-te amb taules dinàmiques.
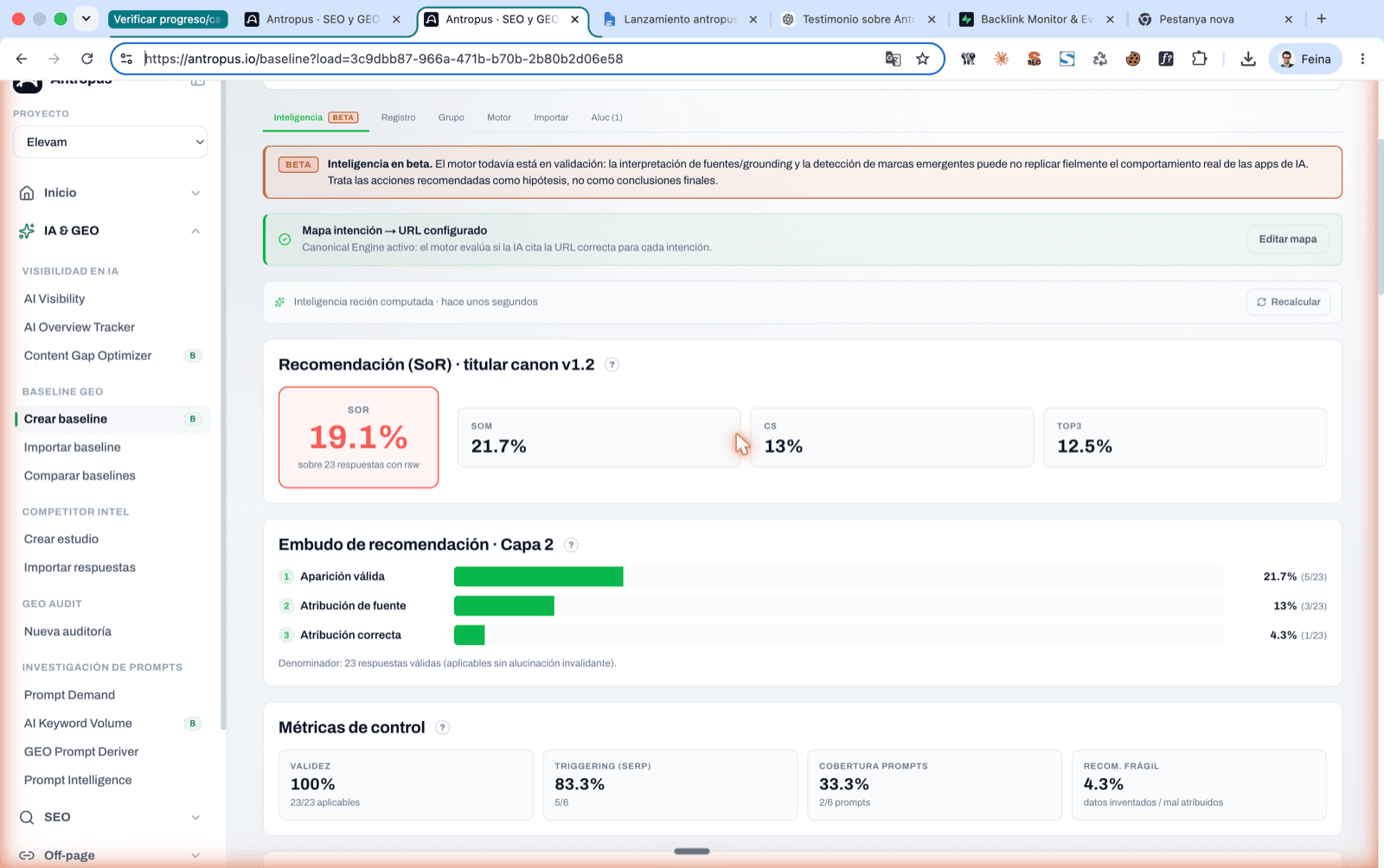
Indicador SoR (titular canon v1.2) i embut de recomanació de 3 capes: aparició vàlida → atribució de font → atribució correcta.
6. El mapa d'intenció → URL canònica: la peça que gairebé ningú mira
Aquí hi ha un dels diferenciadors més seriosos —i més ignorats— d'una auditoria GEO ben feta. Gairebé totes les eines mesuren "la IA va citar alguna URL del teu domini?" com un sí/no. I això es queda curt.
El que de debò importa és:
Va citar la URL correcta del teu domini per a aquesta intenció?
Si un usuari pregunta "millor agència de GEO a Madrid" i la IA cita el teu blog (/blog/que-es-geo/) en comptes de la teva landing de serveis (/servicios/geo-madrid/), tècnicament "et van citar". Però estàs regalant el clic comercial a una pàgina informativa que probablement no converteix. A això ho anomenem drift canònic.
6.1 Què és el mapa d'intenció
L'Intent URL Map és una configuració a nivell de projecte on declares, per a cada clúster d'intenció, quina és la URL canònica esperada del teu lloc. Cada clúster porta:
- Nom (p. ex. "Serveis GEO Madrid", "Marca / reputació", "Comparativa vs SEMrush")
- URL canònica esperada (l'òptima per a aquesta intenció)
- URLs acceptables (altres de teves que també compten com a encert)
- URLs problemàtiques (les que NO haurien d'aparèixer aquí, amb el seu motiu)
- Categories metodològiques que cobreix (quines d'A–F)
- Rol estratègic (reconeixement d'entitat, captura comercial, shortlist de comparació, etc.)
6.2 Les deu classificacions canòniques
Per a cada test, el motor canònic classifica la resposta en una de deu categories, amb una puntuació de 0 a 100:
| Classificació | Puntuació | Significat |
|---|---|---|
| Canònica correcta | 100 | Cita la URL canònica exacta |
| URL acceptable del clúster | 75 | Cita una URL acceptable del mateix clúster |
| URL pròpia, intenció equivocada | 50 | Cita una URL teva, però no la canònica ni una acceptable |
| Actiu de research absorbint intenció comercial | 40 | El teu blog/recursos absorbeix intenció comercial |
| Home absorbint intenció específica | 35 | El teu home absorbeix una intenció concreta |
| Font externa substituint actiu propi | 25 | Citen tercers però cap URL teva |
| Dispersió de fonts | 20 | Diverses URLs teves competeixen per la mateixa intenció |
| Sense canònica disponible | 0 | Hi ha URLs, però el mapa no declara canònica |
| Domini equivocat | 0 | Les URLs citades no són del teu domini |
| Sense URL | 0 | No hi ha URLs a la resposta |
6.3 Què et torna el motor canònic
- Una puntuació global d'alineació canònica (0–100), calculada només sobre tests avaluables: els "sense URL" i "domini equivocat" no són drift, són no-activació, i no contaminen la puntuació.
- Les teves URLs canòniques més fortes (les que reben encerts consistents) i les més febles (les que apareixen amb puntuació baixa).
- Els casos de drift: llista concreta de respostes on la IA va citar una URL teva equivocada, amb el seu motor, el seu prompt, la URL esperada i la realment citada.
- Els casos de dispersió, agrupats per intenció.
- Els conflictes d'URL: pàgines que vas marcar com a problemàtiques i que efectivament estan apareixent.
6.4 Per què això és feina d'agència facturable
Quan lliures un informe amb casos de drift reals, no li estàs donant al client una opinió. Li estàs dient: "Aquí tens 12 casos on el teu blog està absorbint cerques que haurien d'anar a la teva landing de serveis. Aquí el motiu. Aquí la URL que hauria de sortir. Aquí la que surt. I aquí l'acció: reforçar senyals canònics a la landing i rebaixar el llenguatge comercial del post."
Això és diagnòstic amb evidència. I és feina que tu, com a agència, pots cobrar sense enrojolar-te.
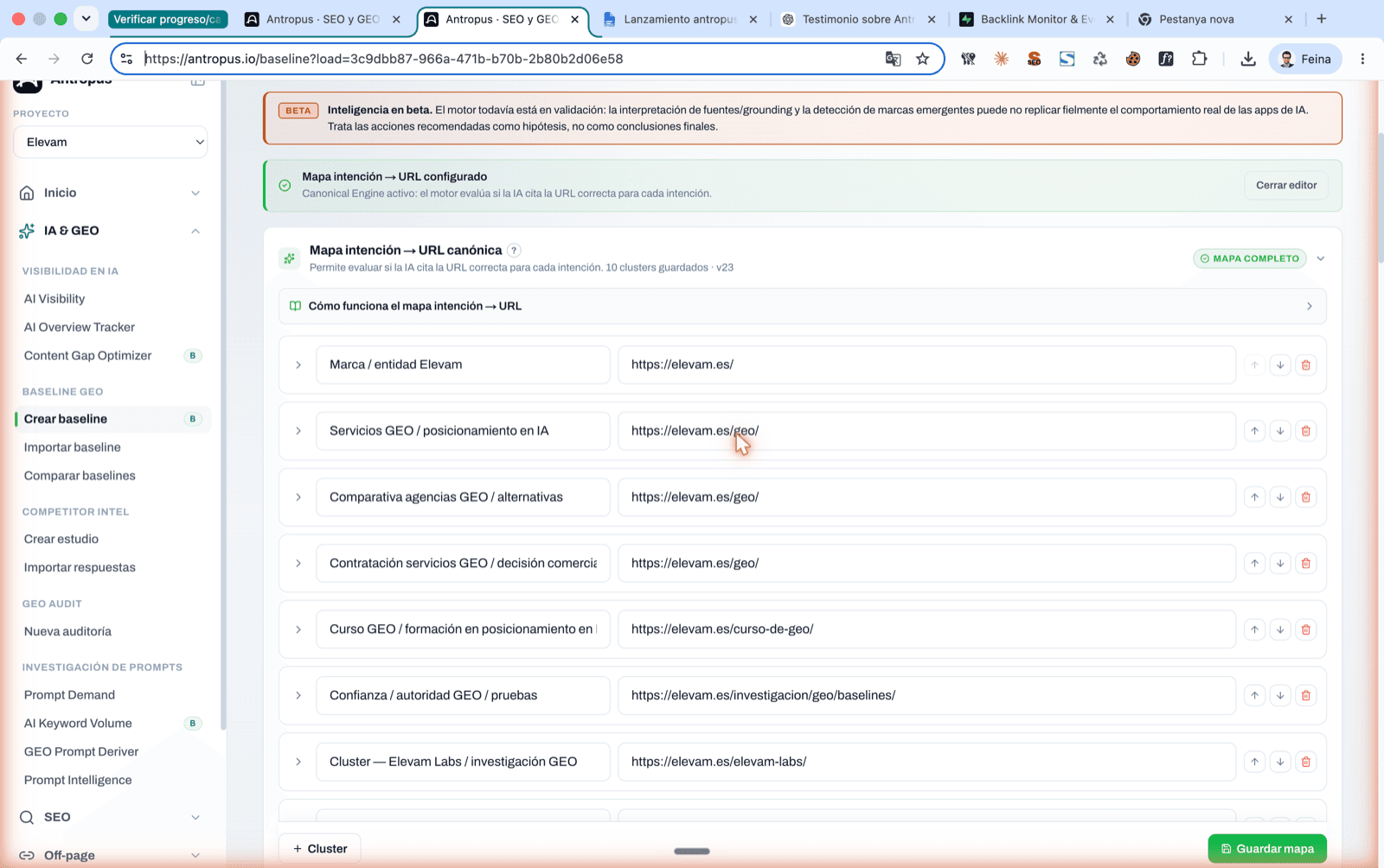
Editor de l'Intent URL Map d'Antropus. Llista de 10 clústers reals del projecte amb URL canònica esperada per intenció i badge "Mapa complet".
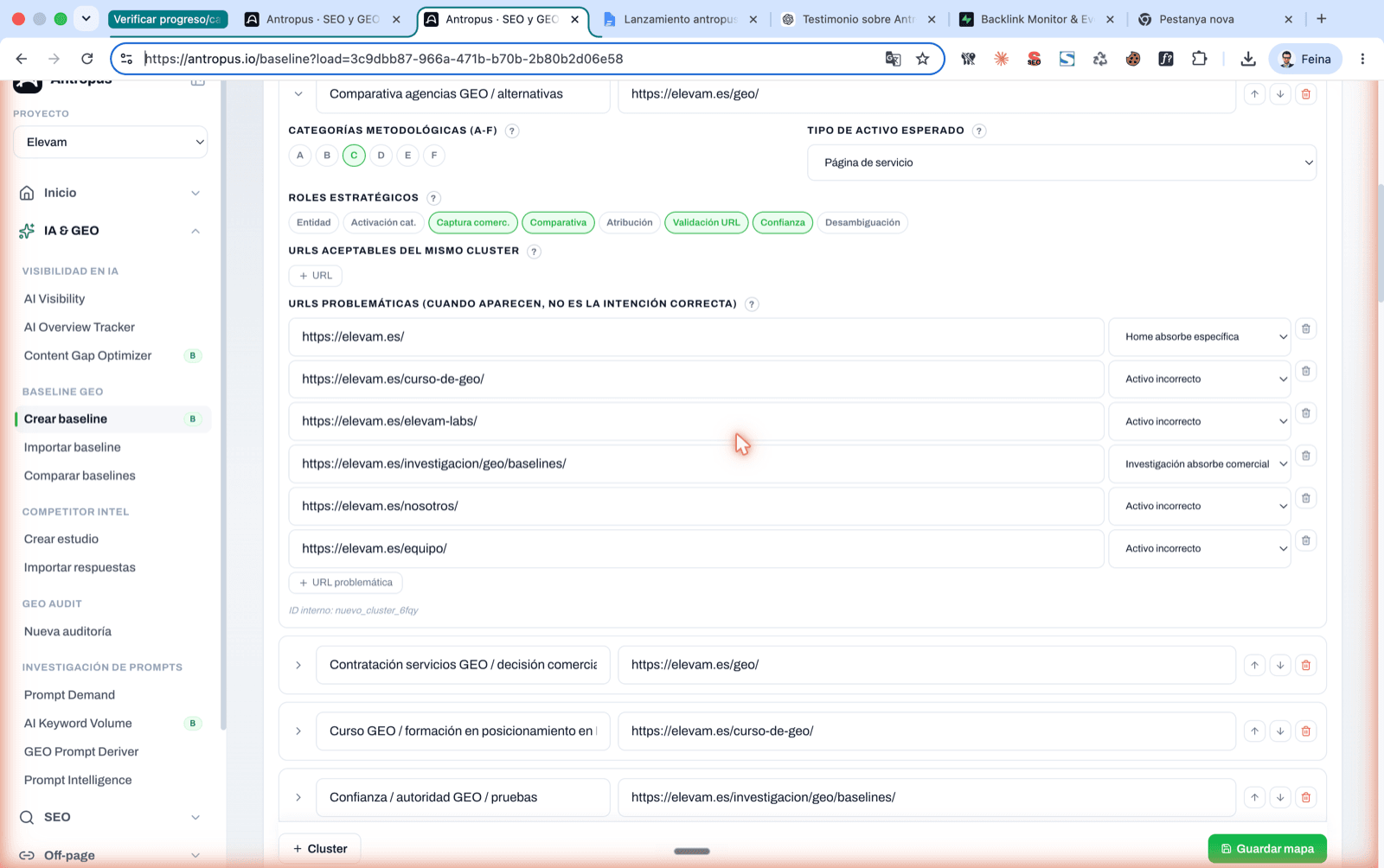
Detall d'un clúster expandit: URLs acceptables del mateix clúster + URLs problemàtiques amb el seu motiu (home absorbeix específica, recerca absorbeix comercial).
7. Com llançar la teva primera auditoria GEO amb Antropus, pas a pas
Anem al gra. Això és, literalment, el que faries avui des de zero per auditar la visibilitat en IA d'un client nou. L'assistent d'Antropus té tres passos: què mesurar, com mesurar i revisar.
7.1 Pas 1 — Què mesurar: identitat del projecte i fitxa d'entitat
Abans de tocar res, configures el projecte: marca, domini, sector, país i fins a tres competidors declarats de manera explícita. Tot això s'omple tirant de la fitxa del projecte si ja existeix.
I tot seguit completes la fitxa d'entitat (Entity Profile). Això és el que permetrà a l'analitzador distingir la teva marca real de qualsevol homònim. Sense una fitxa sòlida, els resultats surten contaminats d'arrel. Els nou camps que omplim sempre:
- Nom canònic (mínim 3 caràcters, no una URL)
- Domini oficial (sense protocol ni www)
- Descripció canònica (factual, idealment de 120 caràcters o més)
- Text de desambiguació (una o dues frases sobre amb quines entitats NO confondre't)
- Àlies (altres noms amb què pot aparèixer la marca)
- Entitats relacionades (persones, productes o conceptes propis que confirmen que la resposta parla de tu)
- Entitats a no confondre (les de nom semblant que NO ets tu)
- Definicions esperades (els teus termes propis i la seva definició canònica)
- URLs oficials (les que compten com a citació correcta més enllà del domini arrel)
Si la teva marca té un nom curt o un homònim, aquest pas és crític. Antropus inclou un assistent "Analitzar web i proposar fitxa" que investiga la marca en fonts públiques i omple els camps. Mai sobreescriu: et mostra el canvi camp per camp i només l'aplica si ho confirmes.
La pantalla et mostra en tot moment l'estat de la fitxa amb un badge ("Llesta per a baseline", "Usable però feble", "Incompleta", "Possiblement invàlida") i el percentatge de completesa. Si la fitxa està en els dos pitjors estats, Antropus desaconsella explícitament llançar el baseline.
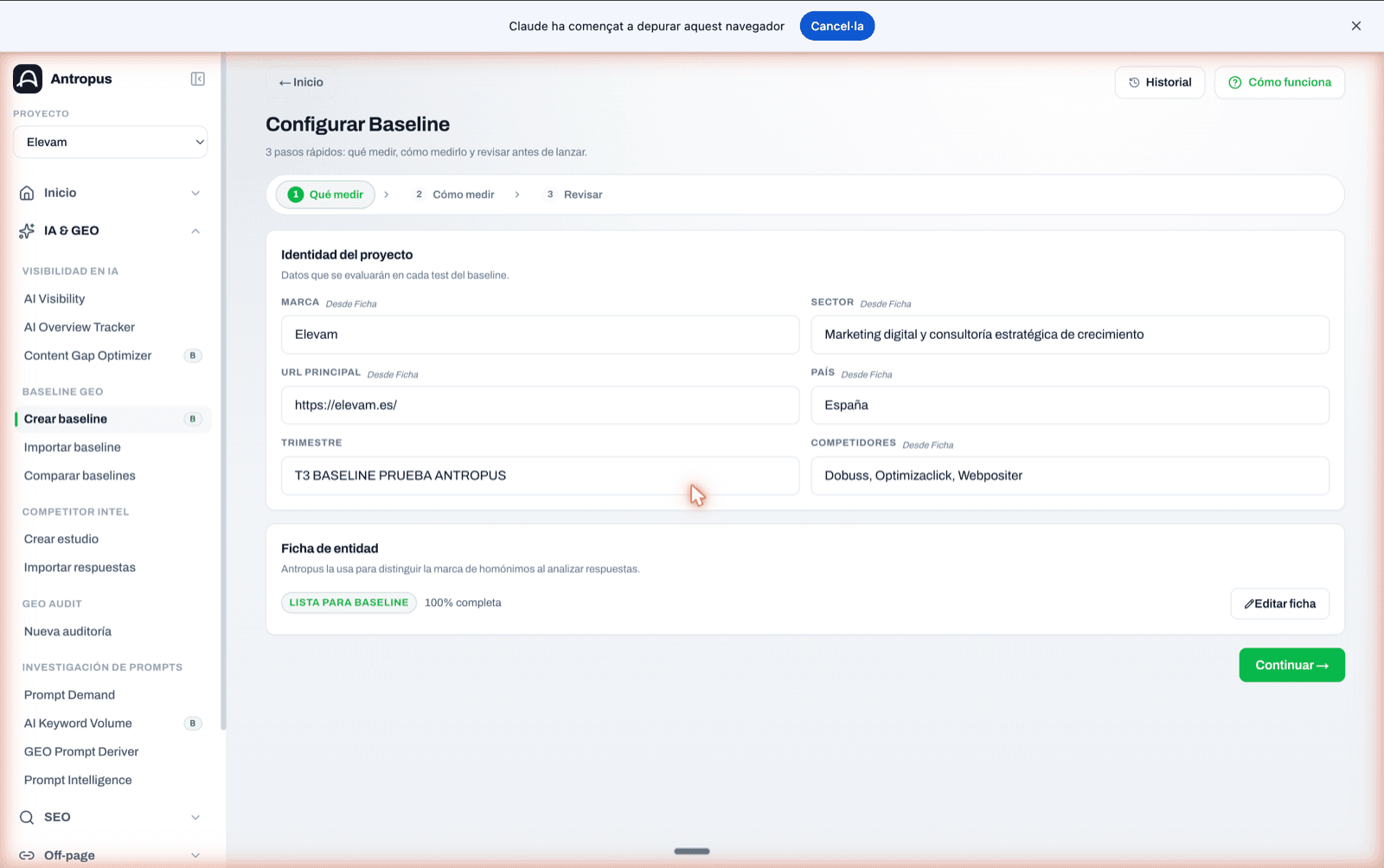
Pas 1 de l'assistent "Què mesurar": identitat del projecte omplerta des de la fitxa i badge verd "Llesta per a baseline · 100% completa" a la secció Fitxa d'entitat.
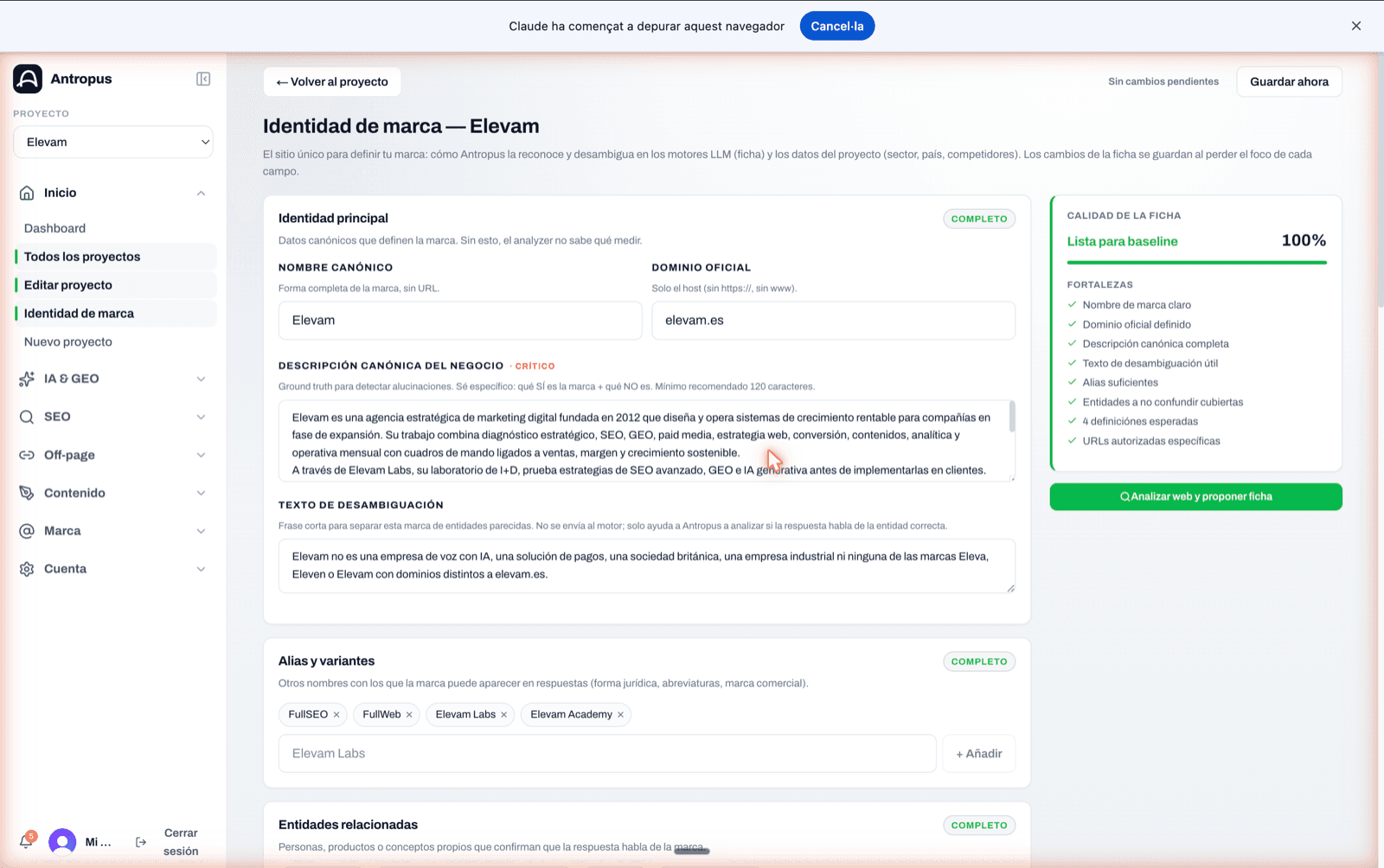
Editor d'Identitat de marca (Entity Profile). Panell lateral amb qualitat 100 %, estat "Llesta per a baseline" i llista de fortaleses detectades.
7.2 Pas 2 — Com mesurar: motors, origen de prompts i profunditat
Aquí decideixes exactament amb què poses a prova la visibilitat de la teva marca. Tres blocs:
Motors. Antropus permet seleccionar manualment, un a un, sobre quines fonts corre el baseline. Les disponibles avui són sis: Claude, ChatGPT, Gemini, Perplexity, Google IA (mode generatiu) i Google AI Overview (el bloc real de la SERP). No hi ha presets: tu tries. Com més motors actives, més fiable la lectura, però també més cost.
Origen dels prompts. Tres opcions: generació metodològica automàtica (Antropus crea els prompts respectant A–F), fer servir un set desat de la biblioteca del projecte, o afegir manualment (enganxant o escrivint). Per a una primera auditoria fem servir l'automàtica; per a auditories recurrents, el set desat, que garanteix que comparem pomes amb pomes trimestre a trimestre.
Profunditat del baseline. Un control lliscant de 5 a 25 prompts. La pantalla indica si l'elecció és "Mesurament mínim" (≤ 5 prompts, prova ràpida amb cobertura limitada) o si entra a la zona metodològicament sòlida (≥ 12 prompts). Els chips A–F a sota recorden quines categories cobrirà el set.
L'elecció de "5 prompts × 4 motors = 20 tests" no és l'habitual d'un client real. Per a un client seriós recomanem com a mínim 15 prompts i 3 motors, cosa que dóna entre 45 i 60 tests. Per a auditoria de capçalera, 30 prompts × 4 motors ≈ 120 tests.
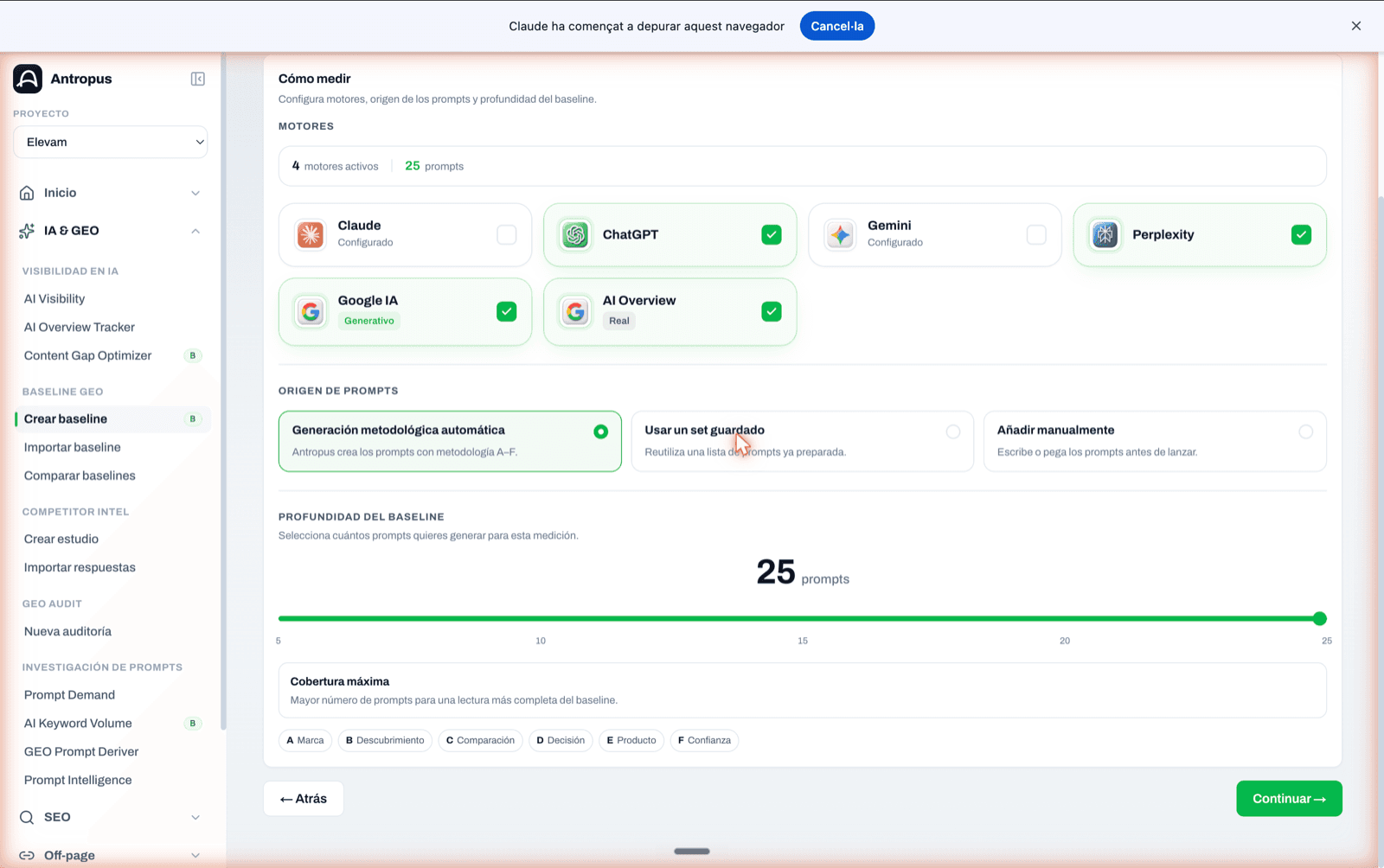
Pas 2 "Com mesurar". Selecció manual dels motors disponibles, origen de prompts i control lliscant de profunditat del baseline.
7.3 Pas 3 — Revisar i configurar el mapa d'intenció
Abans de llançar res, Antropus t'ensenya un resum: motors actius, nombre de prompts, nombre de tests resultants, cost estimat en crèdits, marca, URL, sector, país, competidors i origen dels prompts. És l'última oportunitat de canviar res sense haver gastat.
En aquest mateix pas 3 hi ha, plegat, l'editor del mapa d'intenció → URL canònica. Si el projecte ja tenia mapa configurat, veus un badge "Mapa complet" i el nombre de clústers desats. Si no, pots configurar-lo aquí mateix sense sortir del flux: cada clúster amb la seva URL canònica, les seves URLs acceptables i les seves URLs problemàtiques, amb el motiu de per què són problemàtiques (home absorbeix específica, recerca absorbeix comercial, actiu incorrecte, etc.).
Aquest pas és opcional, però molt recomanat: sense mapa, les mètriques bàsiques (SoR, BCR, Top 3) segueixen funcionant, però perds el 80 % de l'anàlisi estructural —drift, canibalització, recomanacions d'arquitectura—.
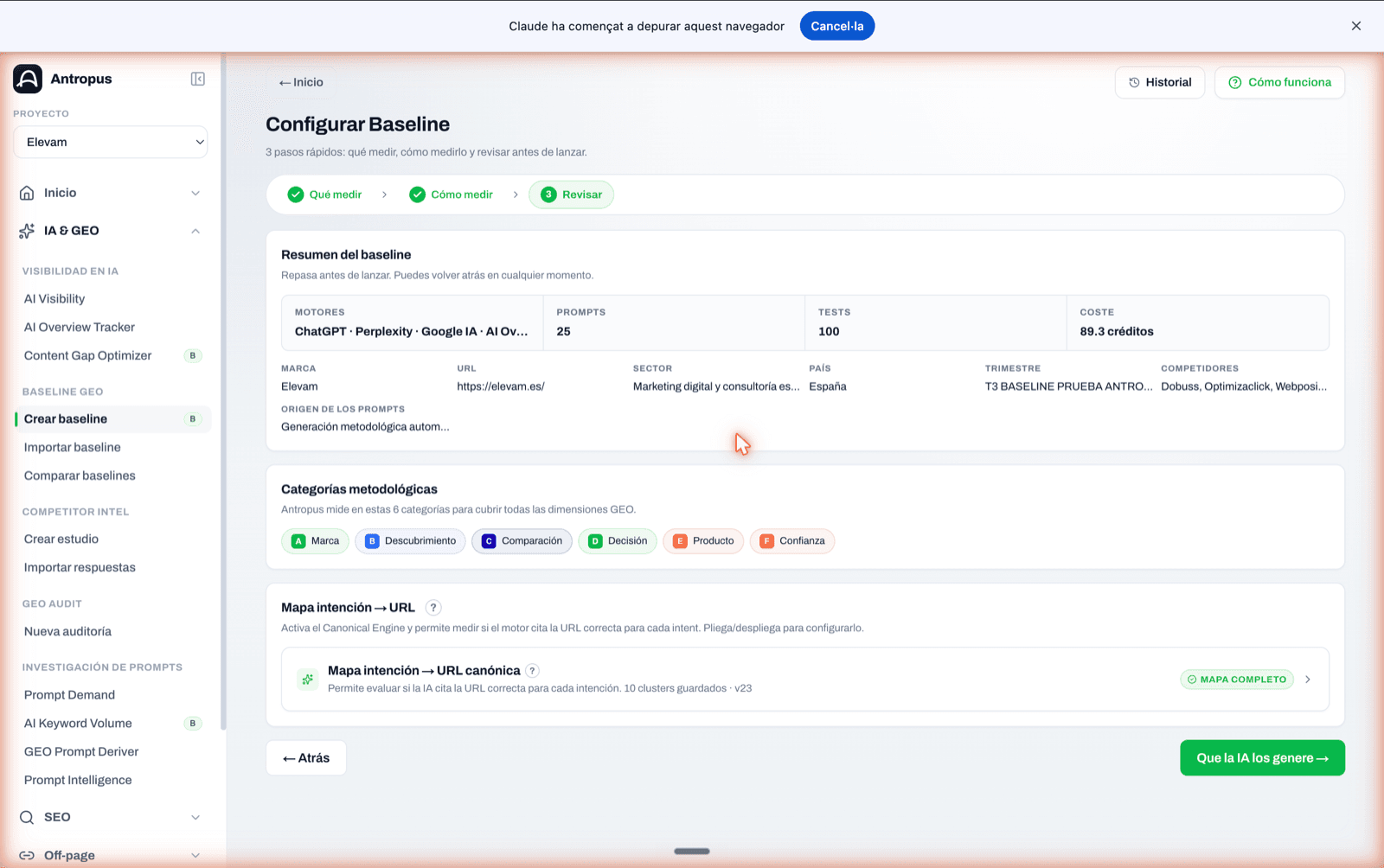
Pas 3 "Revisar": resum del baseline abans de llançar, chips de les sis categories metodològiques i editor del mapa d'intenció plegable.
7.4 Generació i revisió del set de prompts
En prémer "Que la IA els generi", Antropus arrenca un procés visible: analitza el context del negoci, construeix la distribució metodològica, genera per torn cadascuna de les sis categories (B → D → C → A → E → F), valida la distribució global (B+C+D ≥ 51 %, A ≤ 30 %) i detecta biaixos a marca i duplicats semàntics. Ho veus en una llista amb un check verd per cada pas completat.
Immediatament després arribes a la pantalla "Revisar prompts". Allà, abans de llançar, veus:
- El panell de distribució metodològica, amb una puntuació global i avisos quan alguna cosa no quadra (per exemple, "B+C+D representen 50 % del set. Mínim metodològic 51 %").
- La llista de prompts agrupada per categoria A–F, amb el seu text, la seva categoria i la columna "URL canònica" per prompt.
- Una dada important: si tens mapa d'intenció configurat, Antropus autocompleta automàticament la URL canònica de cada prompt segons la seva categoria. A la pantalla apareix un avís ("X URLs canòniques autocompletades des del mapa d'intenció") i els prompts entren ja amb la seva URL alineada. Si vols una URL diferent per a un prompt concret, la sobreescrius allà.
- Botons per afegir prompts a mà, enganxar-ne diversos alhora, copiar la llista o tornar a l'origen.
Encara que Antropus els generi amb metodologia, sempre revisem abans de llançar. Reescrivim els prompts que no tenen l'angle natural del sector, recategoritzem els mal classificats i desactivem els que no apliquen (sense esborrar-los, per si es reactiven el trimestre que ve).
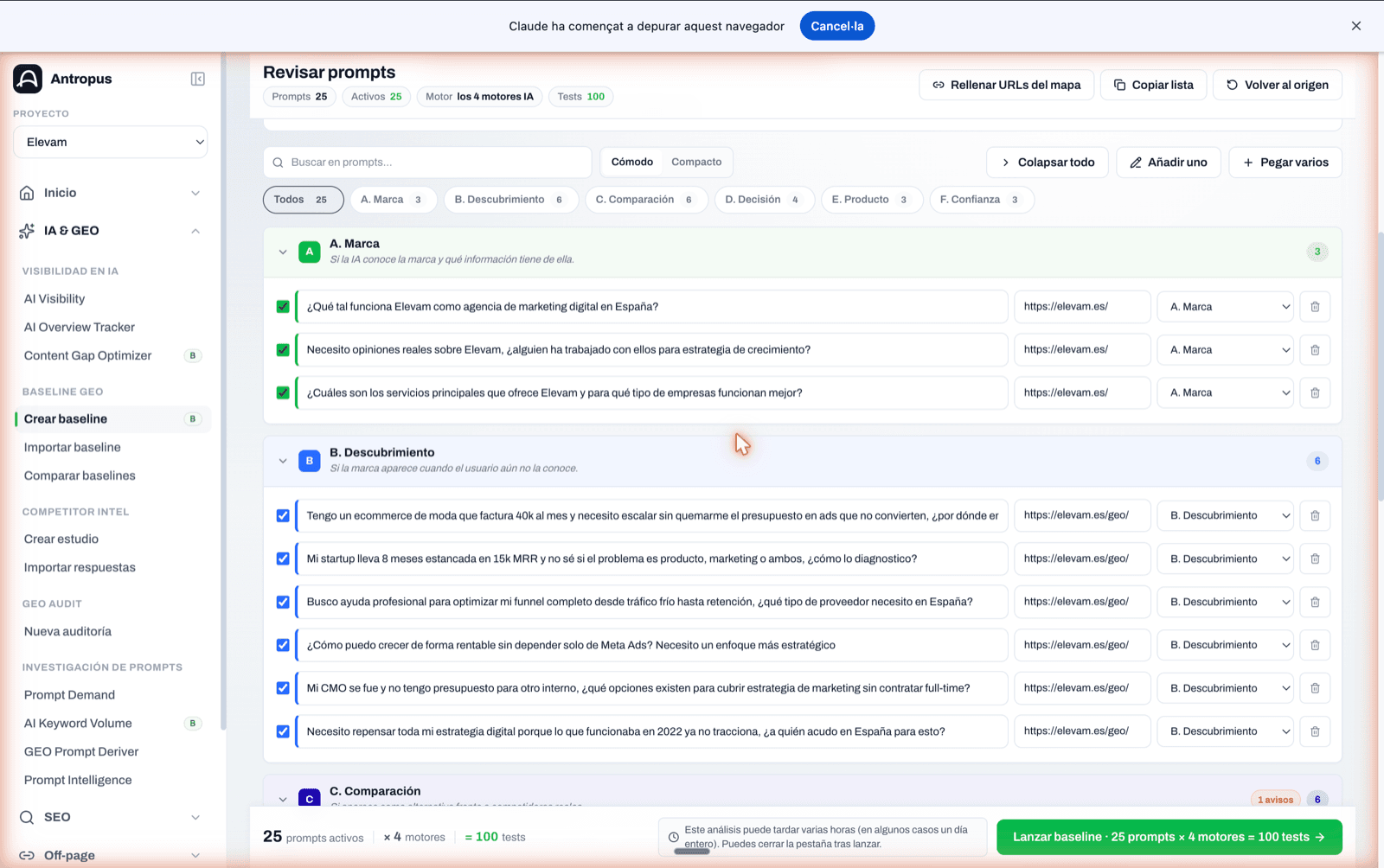
Pantalla de revisió de prompts: cada categoria A–F com a secció col·lapsable, amb el seu text, URL canònica autocompletada i selector de categoria.
7.5 Llançar i monitoritzar
Prems "Llançar baseline" i la feina s'encua al backend, que corre asíncron per lots i va desant el progrés. A la pràctica, això significa tres coses que importen més del que sembla:
- Pots tancar la pestanya. El baseline segueix corrent i, en tornar, veus el progrés real.
- Si un motor falla tècnicament (timeout, quota), aquest test es marca com a fallit i el lot continua. La feina no cau sencera per un proveïdor que va tenir un mal dia.
- Pots cancel·lar a mitges si veus que alguna cosa va malament; els tests ja completats es conserven.
La pantalla "Baseline en curs" té un nucli de progrés ("AI Execution Core") amb un anell SVG, el percentatge gran al centre i nodes per motor al voltant (verd = completat, blau = en curs, gris = pendent). Una barra lineal a dalt mostra "X/N tests" i "X % completat". Més avall: cards per motor amb el seu estat individual, prompt actual destacat, cua de prompts pendents i una línia de fases.
Un baseline petit (5 prompts × 4 motors = 20 tests) triga entre 3 i 8 minuts. Un d'estàndard (30 prompts × 4 motors = 120 tests) pot anar-se'n a 20–35 minuts segons el rendiment dels proveïdors.
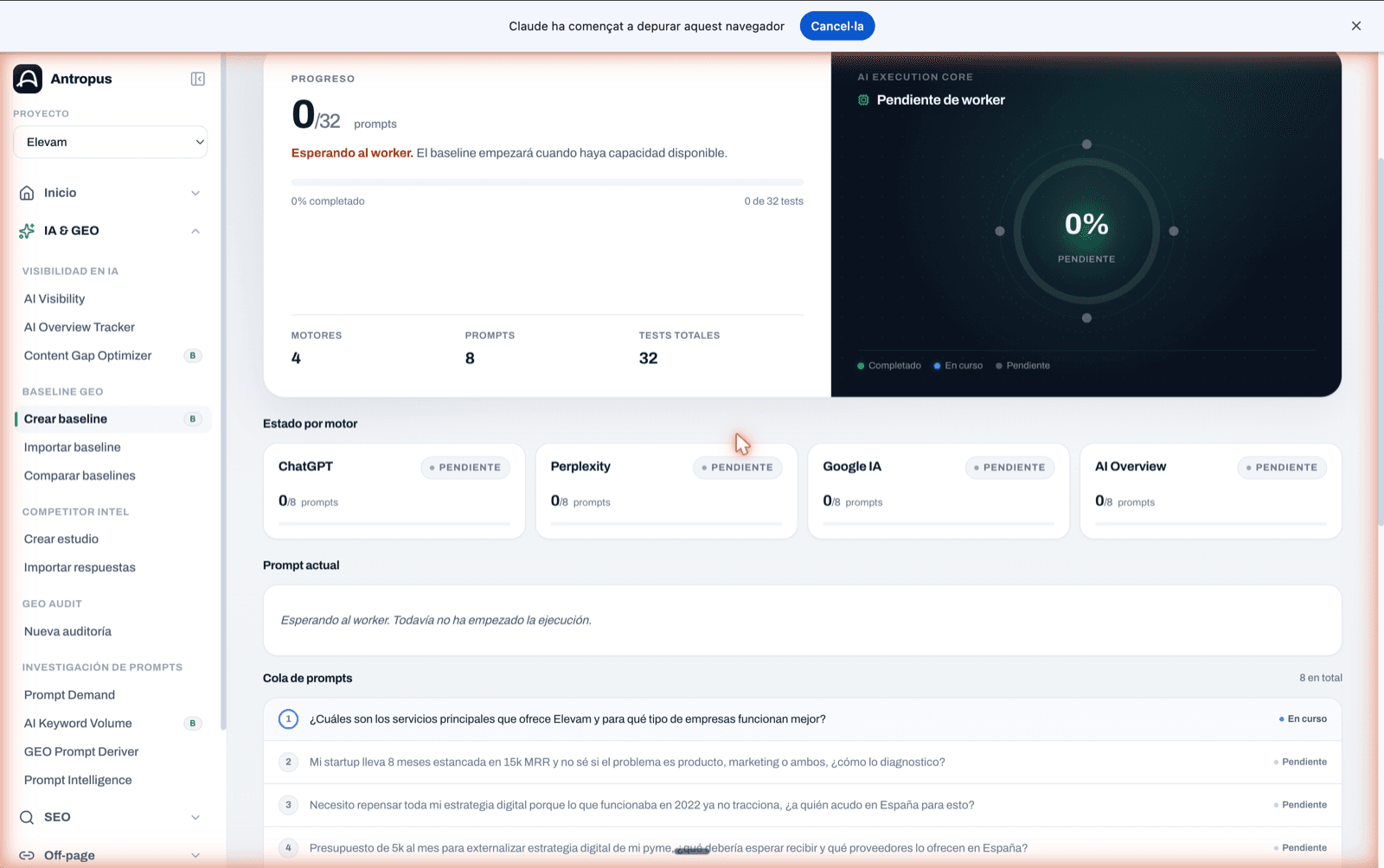
AI Execution Core: anell SVG amb percentatge al centre i nodes per motor al voltant (verd = completat, blau = en curs). Cards per motor + prompt actual.
8. Com llegir i interpretar els resultats
Aquí comença la feina de consultor de debò. Antropus et dóna els números i el diagnòstic estructurat; tu els converteixes en recomanacions. Aquestes són les quatre lectures que fem sempre.
8.1 Lectura 1 — Els quatre indicadors de capçalera
Les combinacions de SoR, BCR, R i Top 3 et donen la foto macro d'un sol cop:
- SoR alt + BCR baix: la IA et recomana però no t'enllaça. Problema de citació, no de visibilitat.
- BCR alt + R baix: t'enllacen, però a la URL equivocada. Problema de canònica, no de citació.
- R alt + Top 3 baix: la URL correcta apareix, però no a dalt. Problema de rellevància o autoritat per a aquesta intenció.
- Tots baixos: problema de fons. Probablement falten senyals d'entitat o el client no té contingut suficient.
Aquest és el primer tall de l'informe.
8.2 Lectura 2 — La taxonomia d'errors
Antropus classifica els errors en 15 tipus amb severitat escalada per valor comercial. Agrupats:
- Al·lucinacions: confusió d'entitat; ambigüitat de sigles; atribució errònia d'autoria; desviació de tema; afirmació favorable sense font; URL que no respon a la intenció.
- Canònica: drift canònic (URL pròpia diferent de l'esperada); dispersió de fonts; feblesa de font pròpia (et mencionen, però sense citar res teu).
- Fonts: dependència de tercers (la teva visibilitat penja només de fonts alienes); dominància de competidors (citen la competència i a tu no, o no al top 3).
- Activació: error d'activació de categoria (pregunta sense marca i sense menció a B/D/E/F); error de shortlist comparatiu (categoria C sense top 3).
I cada error ve amb quatre coses: un títol humà ("Drift canònic", "Confusió d'entitat"…), una descripció de què passa, el seu impacte en llenguatge de negoci ("pèrdua de control de la URL que captura demanda comercial") i un tipus de solució suggerida que enllaça directament amb l'eina d'Antropus que el resol.
8.3 Lectura 3 — Severitat escalada per valor comercial
Un drift canònic en categoria A (marca) és severitat alta. El mateix drift en categoria D (decisió comercial) escala a crítica, perquè costa diners de debò. Les categories d'alt valor són D (decisió), C (comparació) i B (descobriment): qualsevol error en elles puja un esglaó de severitat respecte al mateix error en A, E o F.
Això t'estalvia feina: quan lliures l'informe, les accions prioritzades no són "les que tenen més errors", sinó les que més impacte comercial tenen.
8.4 Lectura 4 — Accions recomanades amb criteri d'èxit
Cada error genera una acció amb prioritat (1–3), una eina destí (un enllaç directe a la funció d'Antropus que el resol: editor d'entitat, copywriter, arquitectura de contingut…) i un criteri d'èxit mesurable. Per exemple: "Citation Rate ≥ 50 % en categoria D al pròxim baseline."
Això és el que lliures com a full de ruta. No "la teva visibilitat és mitjana" (inútil), sinó "aquests set problemes, en aquest ordre, amb aquesta eina, i validem el resultat amb aquesta mètrica d'aquí a tres mesos".
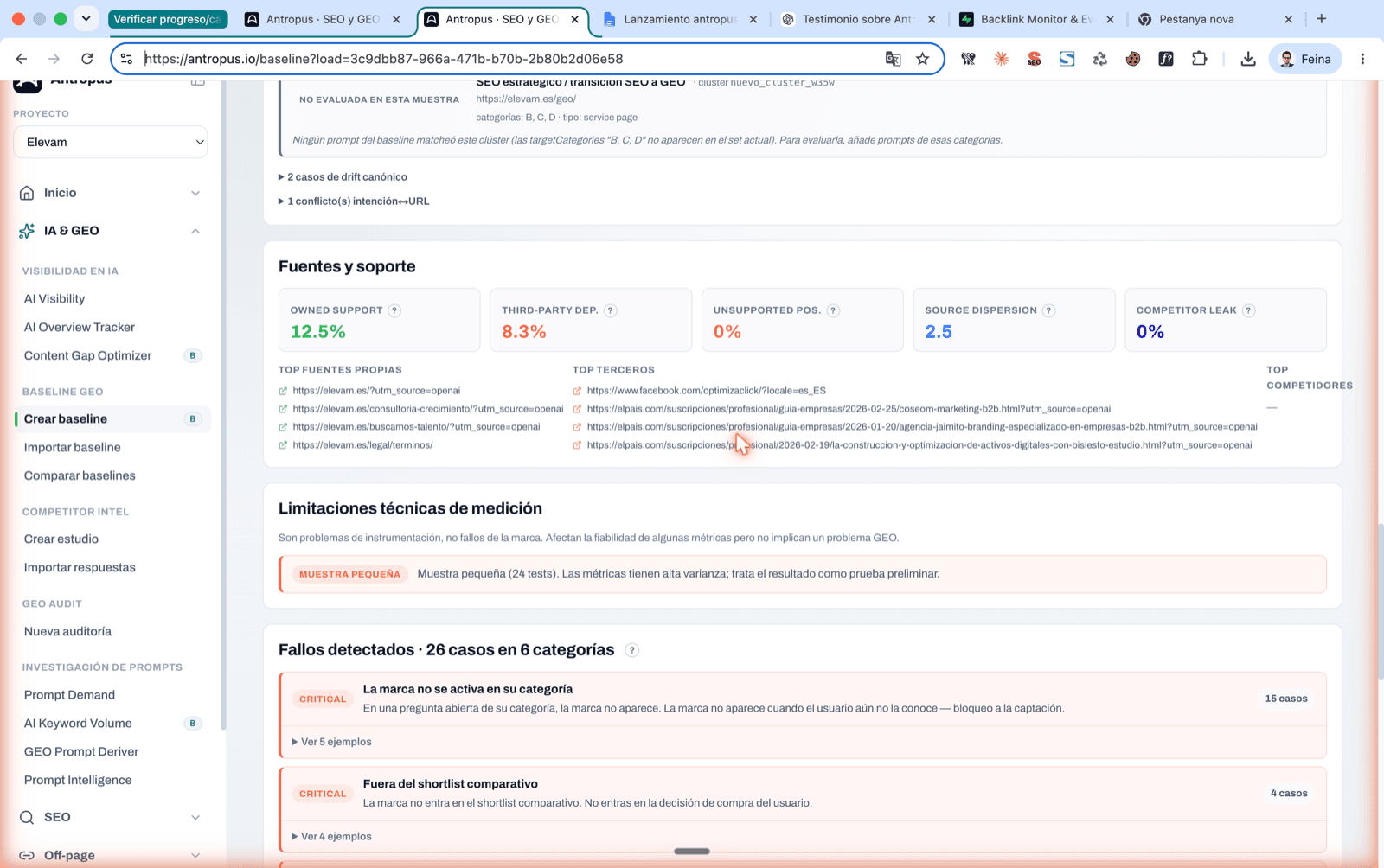
Pestanya "Intel·ligència" amb errors detectats classificats per severitat, accions prioritzades amb la seva mètrica objectiu i criteris d'èxit.
9. L'avís metodològic i la traçabilitat estadística
Una auditoria seriosa reconeix els seus límits per escrit. A Antropus, tot PDF exportat porta un avís metodològic automàtic. I per sota, el motor aplica una sèrie de regles d'honestedat estadística que la majoria d'eines es salten. Les dues coses, juntes, són el que de debò diferencia un informe que aguanta una revisió externa d'un que cau a la primera punxada.
9.1 El que la teva auditoria GEO ha de declarar (sempre)
- Els models d'IA no són deterministes. La mateixa pregunta pot donar respostes diferents en execucions seguides. Per això un baseline és una mostra, no una veritat absoluta. Per detectar canvis reals, comparem diversos tests per motor i mirem la variància.
- El grounding web és imperfecte. Les cerques web dels proveïdors poden tornar fonts incorrectes o no tornar-ne cap malgrat haver-les consultat. Antropus ho detecta i ho assenyala (per exemple, les redireccions opaques de Gemini, que oculten el domini real sota URLs del tipus vertexaisearch.cloud.google.com/grounding-api-redirect/…).
- Les marques semblants es confonen. Sense una fitxa d'entitat ben feta, els homònims produeixen falsos positius. Antropus puntua la qualitat de la fitxa en quatre estats i desaconsella mesurar si està en els dos pitjors.
- Les mostres petites tenen molta variància. Antropus desaconsella treure conclusions de baselines amb menys de 15 prompts. Una mètrica sobre 5 avaluables no té poder estadístic.
- No prometem "posició garantida a ChatGPT". El model canvia, el mode canvia, l'app canvia. El que sí que prometem és metodologia repetible i diagnòstic clar. Qui et prometi el primer t'està venent fum.
- El Triggering Rate d'AI Overview varia. No totes les cerques activen el bloc generatiu. Antropus ho mesura i separa "Google no va mostrar el bloc" de "la teva marca no va aparèixer", dues coses que la majoria d'eines barregen.
Declarar aquests límits no et resta credibilitat. Te'n dóna. El client que entén que una eina reconeix els seus marges d'error és el mateix que confia en tu el trimestre següent.
9.2 Les set regles d'honestedat estadística
- Si no es pot mesurar, no s'inventa. Quan el denominador és 0, la mètrica és "no mesurable", no 0. Al tauler surt "—"; a l'Excel, buit. Un 0 silenciós enganya el client.
- El "no mesurat" es filtra del SoR. "No ho he mesurat" no és "és la pitjor opció". Distingir-ho és la diferència entre un SoR honest i un de corromput per baselines vells.
- Els tests amb confusió d'entitat surten del denominador de visibilitat. Si Gemini et va confondre amb un homònim, aquest test no infla el teu SoM: entra a la taxa de validesa metodològica.
- L'heterogeneïtat es declara. Si la diferència entre el millor i el pitjor motor supera els 40 punts percentuals, el global es marca com a heterogeni i el tauler avisa que no treguis conclusions de la mitjana, perquè un motor l'està distorsionant.
- A la SERP generativa, "es va disparar" i "no es va disparar" van separats. Si Google no va mostrar el bloc, aquest test no entra a visibilitat: entra a Triggering Rate. Mètriques diferents, interpretacions diferents.
- Avisos automàtics per mida de mostra. Menys de 12 prompts: avís. Menys de 15: recomana ampliar. Menys de 5 avaluables: el motor d'intel·ligència es nega a diagnosticar.
- La fiabilitat de fonts pondera per opacitat. Les URLs opaques (les redireccions de Gemini) penalitzen la puntuació; les auditables la pugen. La quota de veu ponderada fa servir aquesta puntuació, de manera que una menció a Perplexity amb font oficial pesa més que una a Gemini amb redirecció.
Detall de l'Excel descarregable. Quan una mètrica no es pot calcular, la cel·la porta "—" en comptes de "0"; taula neta, sense colorins.
10. Quant es triga a fer una auditoria GEO seriosa?
Perquè tinguis una referència real, aquest és el desglossament d'una auditoria completa tal com la lliurem a Elevam:
| Fase | Temps |
|---|---|
| Setup del projecte + fitxa d'entitat | 30–60 min |
| Mapa d'intenció | 45–90 min (segons la mida del lloc) |
| Generació de prompts | 5 min (auto) + 15–30 min de revisió humana |
| Execució del baseline (30 prompts × 4 motors ≈ 120 tests) | 20–35 min automàtic |
| Anàlisi i redacció de l'informe | 2–4 hores |
| PDF/Excel lliurable (amb avís metodològic inclòs) | 30 min automàtic |
En total, aproximadament una jornada de feina de consultor. Si el client vol màxima profunditat (60 prompts × 6 motors, al voltant de 360 tests amb tots els SERP-generatius actius), s'en va a jornada i mitja. Però el resultat justifica sense problema una factura de quatre xifres —sovint de diversos milers d'euros—, sobretot si ho empaquetes bé (auditoria puntual, o auditoria + remediació + segon baseline per validar resultats).
11. Errors que veiem una vegada i una altra en auditories GEO prèvies
Quan un client ens ensenya l'auditoria que li van fer abans, gairebé sempre trobem els mateixos errors:
- Van mesurar només a ChatGPT. Com si fos l'únic motor. Claude, Gemini, Perplexity i el bloc AI Overview de Google també tenen audiència, i els resultats poden ser molt diferents. Una auditoria seriosa mesura en almenys tres motors.
- No separen memòria de web. Els resultats canvien radicalment. Un baseline seriós mesura els dos modes on el motor ho permet i, a més, inclou el SERP-generatiu de Google per veure què explica Google sense que l'usuari abandoni el cercador.
- El SoM surt al 80 % perquè el set era 100 % de marca. Ja ho hem dit, però val la pena repetir-ho.
- No hi ha fitxa d'entitat. L'analitzador no distingeix la marca dels seus homònims. Falsos positius sistèmics.
- No hi ha mapa d'intenció. Només miren "va sortir alguna URL del domini?". No detecten ni canibalització ni drift.
- Mètriques sense denominador. "Citation Rate 35 %." Sobre què? Tests totals? Avaluables? Visibles? Sense saber-ho, el número és soroll.
- Promeses impossibles. "Sortiràs al top 3 de ChatGPT en 90 dies." Això no es pot prometre, perquè ni el model, ni el mode, ni l'app són estables.
Quan arriba un client amb un informe així, la conversa és fàcil: "això no és una auditoria GEO, és el material de venda del que te la va fer. T'ensenyo com es fa bé".
12. Preguntes freqüents sobre l'auditoria GEO
Què és exactament una auditoria GEO?
És el mesurament sistemàtic de com apareix la teva marca a les respostes dels motors d'IA generativa (ChatGPT, Claude, Gemini, Perplexity) i al bloc AI Overview de Google: si et mencionen, en quina posició, si citen el teu web i si et confonen amb una altra empresa.
En què es diferencia una auditoria GEO d'una auditoria SEO?
El SEO mesura la teva posició als resultats de cerca de Google. L'auditoria de visibilitat en IA mesura la teva presència dins de respostes generades, que no tenen posicions ni clics a l'ús. Són disciplines complementàries, amb eines i mètriques pròpies.
Com s'evita que les mètriques surtin inflades?
Repartint les preguntes en sis categories obligatòries —amb entre un quart i un terç de preguntes genèriques, on la marca només apareix si de debò se la recomana—, sense comptar com a encert les confusions de marca i mostrant un "—" quan no hi ha mostra suficient per a una xifra fiable.
Quina eina feu servir per fer l'auditoria GEO?
Fem servir Antropus, la plataforma de SEO i GEO desenvolupada per Elevam Labs. Permet mesurar quatre LLMs (Claude, ChatGPT, Gemini, Perplexity) més Google IA i AI Overview, amb resolució d'entitat, mapa d'intenció i un motor que converteix les mètriques en accions prioritzades.
Cada quant convé repetir una auditoria de visibilitat en IA?
El recomanable és trimestral, fent servir el mateix set de prompts perquè la comparativa sigui vàlida. Els models canvien sovint, i només mesurant amb regularitat detectes a temps si la teva visibilitat puja o baixa.
Es pot garantir aparèixer a ChatGPT o a Google AI Overview?
No, i desconfia de qui ho prometi. El que sí que es pot és mesurar amb rigor, diagnosticar on falles i treballar els senyals (entitat, contingut, citacions, arquitectura) que augmenten les teves probabilitats d'aparèixer.
13. Conclusió
Una auditoria GEO seriosa no és llançar 30 prompts a ChatGPT i resumir el resultat en un PDF. És un protocol de mesurament amb metodologia tancada, mètriques que saps calcular, una taxonomia d'errors clara i uns marges d'error declarats.
El que convé endur-se:
- L'auditoria de visibilitat en IA mesura una cosa diferent del SEO clàssic. Necessita eines i metodologia pròpies.
- Els prompts s'han de repartir en sis categories (A–F) amb diferent política de marca. Un set esbiaixat cap a A produeix mètriques inflades i inútils.
- El SoR (ponderat per força de recomanació) és la mètrica titular d'un tauler GEO seriós. El SoM (binari) és secundari.
- El mapa d'intenció → URL canònica activa l'anàlisi estructural: drift, canibalització, URLs problemàtiques. Sense ell, perds el 80 % del valor.
- Les confusions d'entitat no inflen el SoM: surten del denominador. Així s'eviten els falsos positius.
- Si no es pot mesurar, no s'inventa. L'heterogeneïtat es declara. Les mostres petites s'avisen. Això se li explica al client; no s'amaga.
A Elevam fem servir Antropus per a totes les nostres auditories GEO. És el que ens permet respectar tot l'anterior sense feina manual massiva: backend asíncron resilient, un motor d'intel·ligència que converteix mètriques en accions prioritzades i exportable a PDF amb avís metodològic inclòs.
Sobre Antropus
Antropus.io és la plataforma de SEO i GEO desenvolupada per Elevam Labs, el laboratori de producte de l'agència Elevam, dirigida per Asier López Ruiz. Combina dades reals de proveïdors professionals del sector amb anàlisi d'IA pròpia per auditar la visibilitat de les marques tant en cercadors com en motors generatius, en una sola suite i amb un enfocament centrat en l'honestedat de les dades.


