Retirar contenido obsoleto es algo habitual en SEO. El problema es que hacerlo mal puede perjudicar tu posicionamiento orgánico: canibalizaciones, pérdida de autoridad, errores de rastreo, desaparición accidental de URLs que sí aportaban negocio… y el clásico “hemos borrado cosas y ahora ha caído el tráfico”.
En esta guía vas a ver cuándo tiene sentido desindexar, por qué hacerlo, cómo comprobar si una URL está indexada y 9 maneras distintas de eliminar una URL del índice de Google (incluyendo desindexación masiva y desindexación de imágenes). La idea es que elijas el método correcto según tu caso, sin improvisar.
Por qué desindexar una o varias URLs de Google
Antes de explicarte cómo desindexar una página de Google, vamos a ordenar los motivos. Si no sabes “por qué”, elegirás mal el método.
Razón 1: Tienes canibalizaciones malignas
Una canibalización ocurre cuando dos URLs de tu web compiten por la misma palabra clave (o, más precisamente, por la misma intención). Google divide señales entre ambas en lugar de concentrarlas en una. Resultado: ninguna termina fuerte.
La solución habitual aquí no es “noindex” sin más. La solución suele ser consolidar: dejar una URL canónica que se quede el posicionamiento y redirigir la otra.
En la práctica, la forma más limpia es una redirección 301 desde la URL que NO quieres posicionar hacia la URL que SÍ quieres posicionar.
Matiz importante (del post original, y sigue siendo cierto): hay canibalizaciones que no son malas. Si estás 1º y 2º con dos URLs distintas, puede ser aceptable. Si estás 7º y 8º, consolidar suele ayudar a subir.
Razón 2: No hacer perder el tiempo a los crawlers (crawl budget)
Googlebot (y otros crawlers) tienen un presupuesto de rastreo. Cuando se agota el tiempo/recursos asignados a tu sitio, se van. Si tu web obliga al bot a rastrear páginas que no te interesan, estás desperdiciando esa capacidad y ralentizando la indexación/rastreo de páginas importantes.
En ese caso, tiene sentido desindexar o eliminar del índice las URLs que no aportan valor, y ordenar arquitectura/enlazado interno para guiar el rastreo hacia lo que importa.
Razón 3: Contenido obsoleto
Si tienes contenidos antiguos indexados y hoy son obsoletos (y no aportan valor), suele ser mejor retirarlos del índice. O los actualizas con criterio, o los consolidas, o los retiras. Mantener páginas obsoletas indexadas te puede generar tráfico de mala calidad y señales negativas.
Razón 4: Páginas específicas que no deberían indexarse
Hay páginas que normalmente no conviene indexar:
- Landings creadas solo para campañas de Ads.
- Áreas internas.
- Versiones de prueba.
- En muchos casos, ciertas páginas legales duplicadas o sin utilidad de búsqueda (esto depende del proyecto).
La solución habitual es noindex. Y si ya estaban indexadas, entonces hay que desindexarlas con el método correcto (lo vemos más abajo).
Razón 5: URLs canonicalizadas
Cuando tienes páginas muy similares y aplicas una etiqueta canonical hacia la principal (por ejemplo, variaciones de producto), Google tiende con el tiempo a desindexar las duplicadas y quedarse con la canónica. Esto, bien implementado, es normal.
Razón 6: Migraciones web / SEO y entornos de prueba
Las migraciones suelen hacerse en un entorno de prueba (staging). Esa web debería estar en noindex o restringida para evitar que Google indexe la versión de pruebas.
Si Google ya la indexó, es un caso urgente: toca usar retirada rápida en Search Console y, además, asegurar el bloqueo permanente (noindex / restricción / 401 / etc.).
Cómo saber si una URL ya está indexada
Antes de desindexar, confirma estado. No actúes a ciegas.
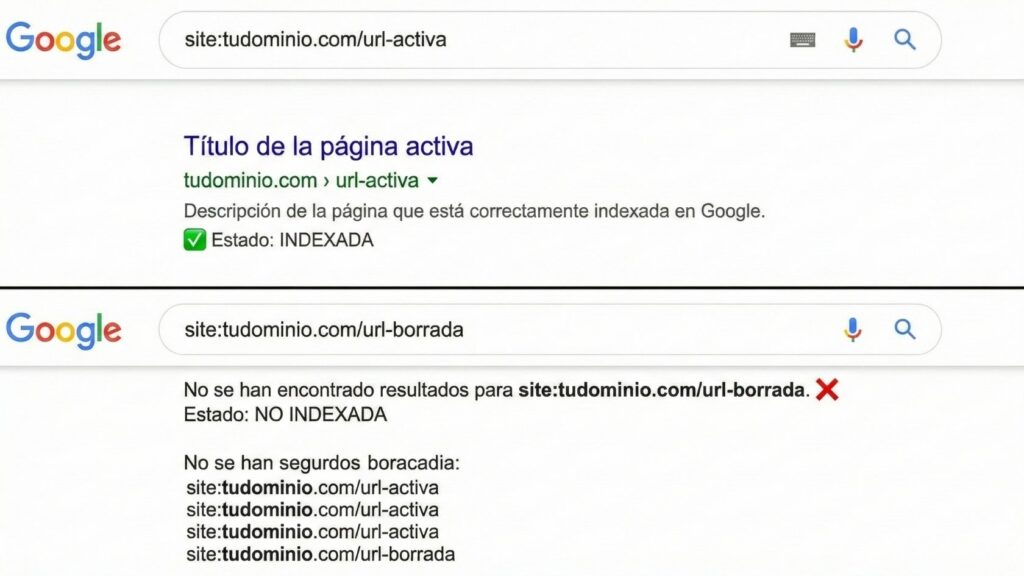
Comprobar una URL concreta con el comando site:
En Google escribe:
site:TU_URL
Ejemplo:
site:mueblesdecocina.com/pared
Si aparece, la URL está indexada. Si no aparece, puede no estar indexada o puede estar indexada pero no visible por cómo Google muestra resultados. Para diagnóstico fiable, usa Search Console.
Comprobar todas las URLs indexadas de un dominio con site:
En Google escribe:
site:TUDOMINIO.COM
Ejemplo:
site:elevam.es
Si no aparecen resultados, es probable que el dominio no tenga nada indexado (o casi nada). Si aparecen, esas URLs están, en principio, en el índice.
Comprobar con Google Search Console (el método que manda)
Search Console te dice el estado real:
- Entra en Search Console.
- Ve a Inspección de URL.
- Pega la URL exacta.
- Te dirá si está indexada y por qué.
Luego, si necesitas desindexar, también lo harás desde aquí.
Qué método usar para desindexar: tabla de decisión rápida
La forma correcta de desindexar depende de si quieres que la URL desaparezca para siempre, si necesitas conservar señales (enlaces), o si solo es un ocultado temporal.
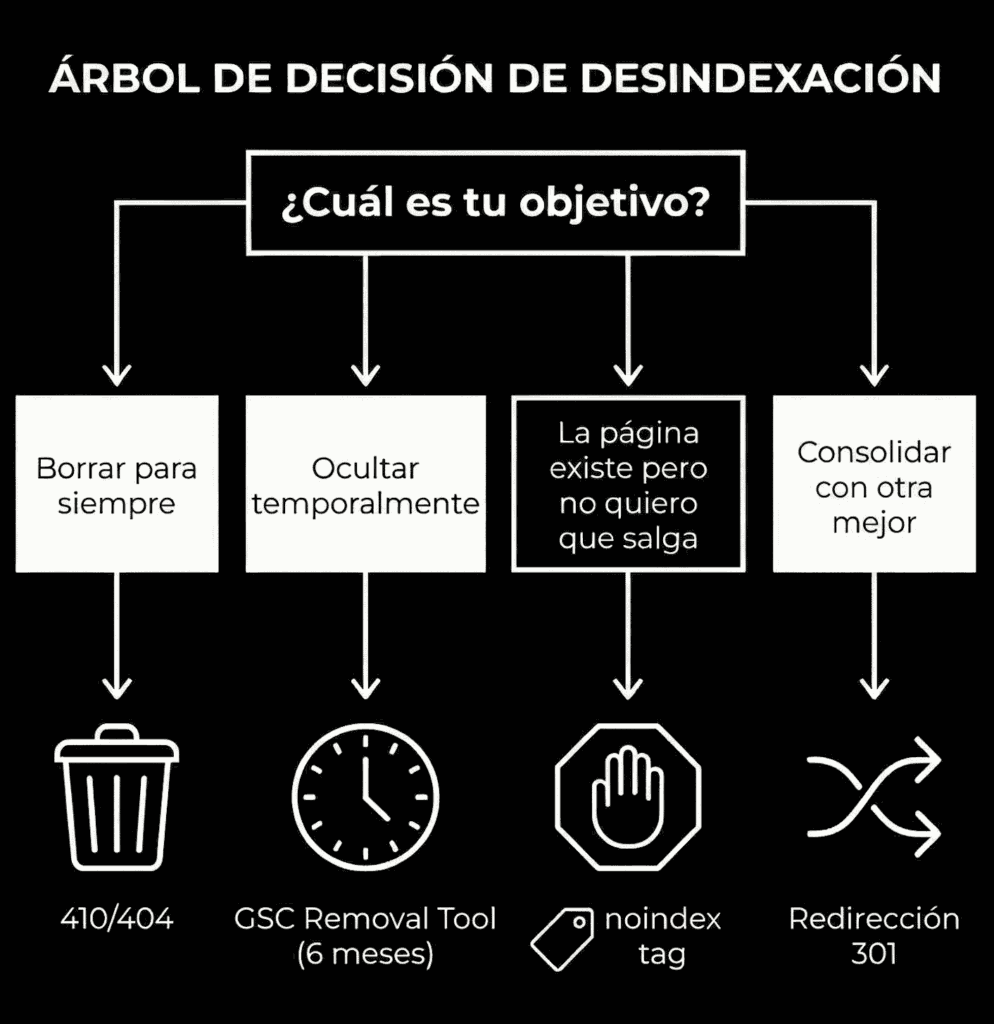
| Objetivo real | Mejor método | Cuándo NO usarlo |
|---|---|---|
| Consolidar y pasar fuerza a otra URL | 301 hacia la URL ganadora | Si no hay una URL equivalente o relevante |
| Eliminar definitivamente (no volverá) | 410 (o 404 si no puedes 410) | Si la URL puede volver o tiene valor residual |
| Que no indexe, pero la página sigue existiendo | noindex (meta o X-Robots-Tag) | Si bloqueas el rastreo con robots, Google no verá el noindex |
| Ocultación rápida en resultados | Search Console: Retirada de URL | Si lo usas como único método (es temporal) |
| Bloquear acceso a todos salvo usuarios autorizados | Restricción (login/HTTP auth/whitelist IP) | Si necesitas tráfico orgánico o indexación |
| Evitar duplicados por páginas similares | Canonical | Si no entiendes bien las implicaciones (Google puede ignorarlo) |
9 maneras para desindexar una URL de Google (o una web completa)
A continuación tienes todos los métodos del artículo original, reordenados y mejor explicados, para que elijas el correcto sin perder señales ni crear problemas nuevos.
1) Herramienta “Eliminar URLs” de Search Console (rápida y eficaz)
En Search Console puedes solicitar la retirada de una URL del índice. Es el método más rápido para “quitarla de la vista” cuando hay urgencia.
Pasos:
- Entra en Search Console.
- Ve a Índice → Retiradas (o “Retirada de URL”).
- Haz clic en Nueva solicitud dentro de Retiradas temporales.
- Introduce la URL a retirar (o el prefijo si corresponde).
- Envía la solicitud.
Importante: esta retirada es temporal. En el post original lo dices claro y hay que mantenerlo: dura 6 meses. Pasado ese tiempo, Google puede volver a indexar la URL si sigue accesible y no hay una medida permanente (noindex/404/410/restricción/etc.).
Traducción: usa Search Console para acelerar, pero siempre acompaña con una medida permanente si quieres que no vuelva.
2) Eliminar el contenido: dejarla en error 404
Si eliminas la página, devolverá 404 (no encontrado). Cuando Google rastree varias veces y confirme que ya no existe, acabará desindexándola.
Si no puedes eliminar la página (porque debe existir para usuarios), este método no es tu mejor opción.
3) Añadir status code 410 (más contundente que 404)
410 significa “Gone”: la página ha desaparecido de forma permanente. Es más explícito que un 404, que podría interpretarse como un error temporal.
Si sabes que esa URL no va a volver y quieres acelerar desindexación, 410 suele ser más directo.
4) Etiqueta noindex (meta robots o X-Robots)
El objetivo de noindex es indicar al buscador: “puedes rastrear esta página, pero no la indexes”.
Ejemplo de meta robots noindex:
<meta name="robots" content="noindex">Dos puntos críticos (del original, y fundamentales):
- Los crawlers deben poder acceder a la página para ver el noindex.
- Si bloqueas la URL en robots.txt, Google puede no ver el noindex y la desindexación se complica.
Cuándo noindex puede no ser tu mejor solución:
- Si los usuarios tampoco deberían acceder (mejor restricción).
- Si necesitas consolidar señales/enlaces (mejor 301 o canonical según el caso).
5) Disallow en robots.txt (más “prevenir” que “curar”)
robots.txt bloquea el acceso de los crawlers a una URL o sección. Sirve para evitar rastreo, pero no es el método más fiable para desindexar si la URL ya está indexada.
Advertencia importante: si una URL está en noindex pero la bloqueas en robots, Google no puede entrar a verla y puede tardar más en desindexar. Esta combinación suele ser mala idea.
Úsalo sobre todo para prevenir indexación de secciones completas (por ejemplo, recursos internos), no como solución principal de desindexación.
6) Cabecera HTTP X-Robots-Tag: noindex
Es equivalente a noindex, pero aplicado en cabecera HTTP (útil en preproducciones, PDFs, o reglas a nivel servidor).
HTTP/1.1 200 OK
X-Robots-Tag: noindexSi tienes un staging o una sección que debe ser accesible pero no indexable, puede ser una opción sólida.
7) Restricción de acceso (login / HTTP auth / whitelist IP)
Si tu objetivo es que determinados usuarios accedan pero los buscadores no, esta es la familia correcta de soluciones.
Opciones típicas:
- Sistema de login.
- Autenticación HTTP.
- Whitelist de IP.
Se usa sobre todo en redes internas, áreas privadas y entornos de prueba. Si está restringido correctamente, Google no debería indexar.
8) Canonicalización
Cuando una página es duplicada o muy similar a otra, puedes usar la etiqueta canonical para indicar cuál es la versión principal.
Matiz importante del original: canonical no es una directiva, es una señal. Google puede ignorarla.
Ejemplo:
<link rel="canonical" href="https://tudominio.com/url-principal" />Úsalo para gestionar duplicidad (variantes, parámetros, versiones). No lo uses como martillo para todo, porque una canonical mal puesta puede cargarse el posicionamiento.
9) Desindexar masivamente mediante sitemap
Cuando quieres desindexar muchas URLs, esperar a que Google las rastree “cuando le toque” puede ser lento. El enfoque del original es correcto: puedes acelerar el proceso forzando rastreo con un sitemap específico.
Cómo se hace:
- Primero aplicas la medida permanente en cada URL (noindex, 404, 410, etc.).
- Luego creas un sitemap específico con esas URLs (o las incluyes en el principal si son pocas).
- Lo envías en Search Console para que Google las rastree con más frecuencia.
- Cuando la mayoría ya esté desindexada, vuelves a dejar el sitemap como estaba.
Este método es especialmente útil en limpiezas grandes, migraciones y recortes de thin content.
Desindexar imágenes
Para eliminar imágenes de Google, el método más habitual es bloquear el rastreo de imágenes con robots.txt para Googlebot-Image. En el post original lo planteas así, y lo mantenemos.
Desindexar una sola imagen
User-agent: Googlebot-Image
Disallow: /url-relativa-imagen.jpgDesindexar todas las imágenes
User-agent: Googlebot-Image
Disallow: /Nota práctica: esto puede tardar en hacerse efectivo. No es instantáneo.
Preguntas frecuentes
¿Eliminar una URL del índice de Google es lo mismo que borrarla?
No. Puedes retirar (temporalmente) con Search Console, puedes desindexar manteniendo la página (noindex), o puedes eliminarla (404/410). Son objetivos distintos con consecuencias distintas.
¿Qué método es mejor: noindex, 404 o 301?
Depende del objetivo: si quieres consolidar y pasar señales, 301. Si quieres retirar definitivamente, 410 (o 404). Si la página debe existir pero no indexarse, noindex (meta o X-Robots).
¿Puedo usar robots.txt para desindexar?
Como método principal, no es lo más fiable. robots.txt bloquea rastreo; si Google no puede ver la señal (noindex/410/etc.), puede tardar más. Es mejor para prevenir que para curar.
¿Cuándo tiene sentido usar la herramienta de retirada de Search Console?
Cuando necesitas ocultación rápida. Pero recuerda: es temporal (6 meses). Acompáñala de una medida permanente si no quieres que vuelva.
Antes de tocar nada: el error que más caro sale
El error típico es desindexar por “limpiar” sin entender intención y señales. Si una URL tiene enlaces, tráfico útil o cumple una función en arquitectura, borrarla sin consolidación puede costarte más que mantenerla.
Regla rápida: si la URL tenía valor, consolida (301 hacia la mejor). Si era basura, elimínala (410/404). Si debe existir pero no indexar, noindex. Y si necesitas ocultar ya, Search Console como acelerador, nunca como solución única.
Nota editorial: ¿Por qué hemos publicado esto?
Porque la desindexación se está usando mal: gente borrando páginas a lo loco, bloqueando con robots.txt sin entender consecuencias, o retirando temporalmente en Search Console creyendo que es para siempre.
El resultado es el mismo: pérdida de posicionamiento por errores evitables y una sensación falsa de “hemos hecho mantenimiento”.
Publicamos esto para fijar criterio y orden: desindexar no es un botón, es una decisión estratégica. Si lo haces con método (intención, consolidación, señales, crawl budget), limpias sin romper. Si lo haces por impulso, te pegas el tiro tú mismo.